eDocPrintPro Version 3.18.2 verfügbar
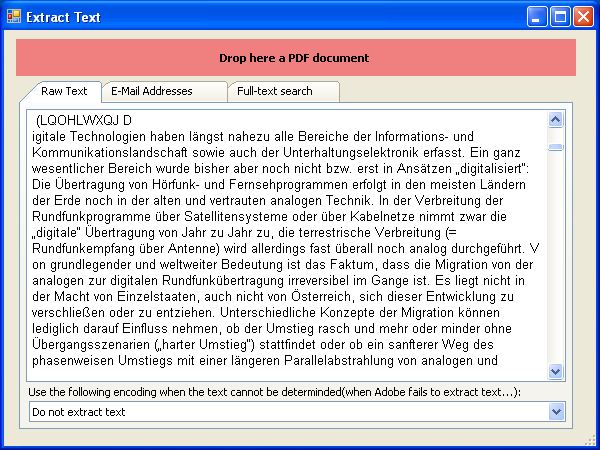
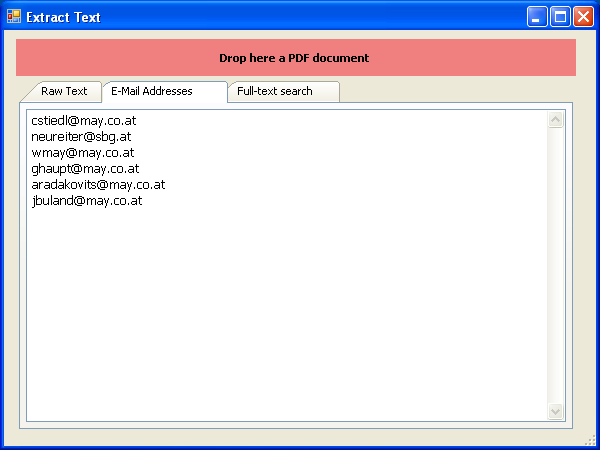
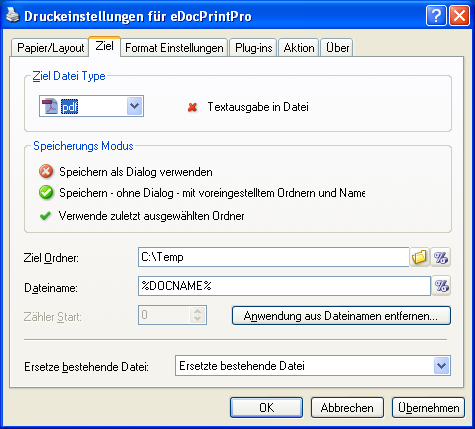
eDocPrintPro kann neben dem PDF auch eine Datei mit ihrem Textinhalt erzeugen. Über diese Datei kann eine nachgelagerte Software weitere Aktionen veranlassen und steuern. So kann z.b. eDocPrintPro auch als Fax Druckertreiber für Telefonanlagen genutzt werden wobei die Fax-Nummer im Dokument mitgedruckt, über die Textdatei ausgewertet und an die Fax-Software übergeben wird. Die Starface Telefonanlage – www.starface.de – unterstützt z.b. eine solche Funktion und liefert eine angepasste Version von eDocPrintPro mit aus.
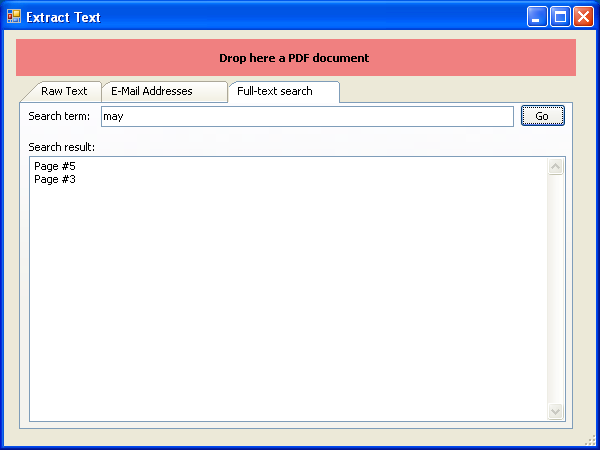
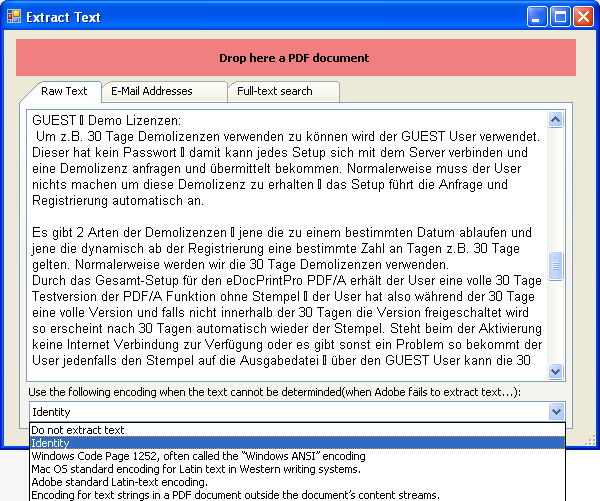
Mit der neuen Version 3.18.2 wurde die Funktion für die Extraktion von Texten aus dem PDF neu implementiert und damit genauer und zuverlässiger gemacht.
Download – eDocPrintPro 32 und 64bit (ca. 30MB) >>>
Download – eDocPrintPro PDF/A 32 und 64bit (ca. 52MB) >>>