ifresco Profiler – Scannen, Bearbeiten, OCR, Barcode, Erfassen von Metadaten, Alfresco Integration
Der ifresco Profiler stellt auf jedem Arbeitsplatz wichtige, einfach zu bedienende seitenorientierte Dokumentenbearbeitungsfunktionen übergreifend für PDF und Imagedokumente zur Verfügung. Es ermöglicht Dokumente mit Metadaten schnell und effizienten mit individuellen und spezifisch angepassten Profilierungsmasken als durchsuchbare PDF´s im Alfresco abzulegen. Bereichs OCR über eine integrierte OCR Engine, Erzeugung durchsuchbarer PDF´s beim Export über die integrierte OCR bzw. externen AutoOCR Server, Barcode Erkennung für Dateiname und Dokumentensplit, Export in Folder, als E-Mail Anhang bzw. über installierbare individuelle Plugin´s zusammen mit Metadaten nach Alfresco, sind einige wesentliche Merkmale der Software.
Die Anwendung besteht aus 2 Komponenten – der Profiler Basissoftware welche alle allgemeinen Funktionen beinhaltet, sowie aus einem oder mehreren installierbaren Plugins. Diese Plugins stellen die Schnittstelle zu Alfresco dar und ermöglichen es individuell an die Anforderungen und Einsatzbereich angepasste Profilierungsmasken zu verwenden. Die komplette Logik für die Metadaten, die Ablagestruktur und die Namensgebung ist in einem Plugin abgebildet.
ifresco Profiler Basis:
- Verarbeitet PDF und Imagedateien – Schwarz & Weiß, Graustufen, Farbe, – ohne auf Unterschiede bei Dateiformat und Farbe achten zu müssen – alle Funktionen sind übergreifend implementiert.
- Integrierte Scanfunktion um Dokumente über lokal angeschlossene Scanner einscannen zu können. Scan Einstellungen können direkt über voreinstellbare Scan-Profile ausgewählt werden.
- Erfassen von Dokumenten aus Foldern – Anzeige als Dokumentenliste z.b. für Multifunktionsgeräte, Netzwerkscanner mit Scan to Folder Funktion oder per Druckertreiber erzeugte, sowie um per E-Mail empfangene Dokumente verarbeiten zu können.
- Schnelländerung der Dokumentennamen – mit automatischer Selektion der nächsten Datei in der Liste nach Abschluss der Änderung.
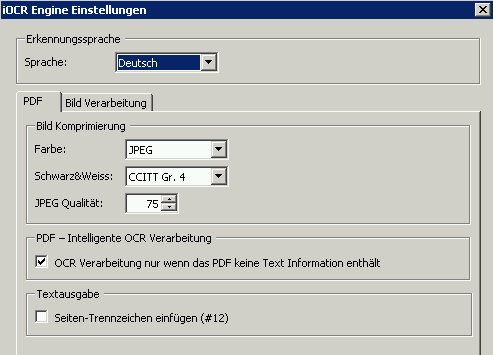
- Bereichs OCR über lokal integrierte OCR Engine um Dateinamen zu vergeben.
- Bereiche löschen / zuschneiden
- Seitenvoransicht – Zoom, Blättern, Seitenauswahl, Drehen – sowie Thumbnail Miniaturen des gesamten Dokuments
- Seitenorientierte Dokumentenbearbeitung – Seiten drehen links, rechts, Seiten löschen, Seiten per Drag&Drop in der Thumbnail Ansicht verschieben.
- Gesamtdokument teilen – an der markierten Seite, nach x Seiten, nach Barcode.
- Einzeldokumente zu einem Gesamtdokument zusammenfügen – Reihenfolge festlegen, automatisches Löschen der Einzeldateien.
- Exportieren – in einen Folder, als E-Mail Anhang versenden, oder über Profilierung mit Metadaten im Alfresco ablegen – im nativen Format, als PDF Image oder als PDF-OCR
- Beim Export – Erzeugung durchsuchbarer PDF-OCR Dokumente über lokal integrierte iOCR Engine oder über den per Web-Service integrierten AutoOCR Server mit Abbyy OCR
- Intelligente OCR Verarbeitung – nur Image Seiten werden OCR verarbeitet – normale PDF Seiten werden unverändert übernommen.
ifresco Profiler plugins:
Die Profilmaske und die Logik der Profilierung für die Ablage der Dokumente im Alfresco wird beim ifresco Profiler über Plugins realisiert. Da jedes Unternehmen ein eigenes Datenmodell und Ablagelogik verfügt werden die Plugins individuell nach Spezifikation entwickelt und implementiert. Hier kann auf eine Basis von bereits realisierten Plugins zurückgegriffen werden. Für Tests sowie zur Veranschaulichung der Möglichkeiten steht ein Standardplugin sowie zur bereits realisierte Plugins Verfügung.
- Installierbare Plugins – für Profilierung und Erfassung von Metadaten zur Ablage von Dokumente in Alfresco.
- Ein oder mehrere Plugins können installiert, ausgewählt und damit auch auf andere Alfresco Server umgeschaltet werden – jeder Plugin beinhaltet seine eigene individuelle Logik für die Profilierung als eigenständig installierte .NET / C# Anwendung die sich in das ifresco Profiler Basisframework einfügt und deren Funktionen nutzt.
- Gleichzeitige Darstellung der Profilmaske und der Dokumentenvoransicht bei der Erfassung der Metadaten.
- Frei programmierbare Logik und Funktionen auf der Profilierungsmaske mit z.b. externe XML Templateregeln mit dynamischen Feldern um den Namen / Titel immer gleich aufzubauen, Zugriff auf externe Datenquellen – MS-XLS, SQL, Web-Service (z.b. SugarCRM), verknüpfte Tabellen und Vorbelegung von Feldern mit Werten aus der Tabelle, Type ahead Teilstring Suche über einzelne oder kombinierte Felder, Verwendung von Alfresco Kategorien als Lookup´s, Zuordnung bestehender Alfresco Tags, Automatische Neuanlage von Tags, Automatisches Erzeugen der Alfresco Folderstruktur sowie der Dateinamen aus Profilfeldwerten, Suche nach Foldern im Alfresco, Counter über Web-Service, Stempelung des Dokuments vor dem Upload mit Infos aus den Metadaten, Suche nach im Alfresco vorhandenen Dokumenten und Übernahme von Profilwerten usw.
- Interaktive Verarbeitung – mit OCR und Upload oder alternativ
- Hintergrund / Batchverarbeitung – für PDF-OCR Konvertierung und Alfresco Upload – der User kann bereits weiterarbeiten während im Hintergrund die OCR Verarbeitung und der Alfresco Upload stattfindet.
- Bestehende Profilwerte erhalten / Maske löschen
- Automatisch Laden des nächsten Dokuments aus der Liste – verarbeitetes Dokument wird nach dem Upload gelöscht oder in einen Archivbereich verschoben.