PDF Image Processing dient dazu die Qualität gescannter Dokumente zu verbessern und zu optimieren bzw. als Vorbereitung für eine nachfolgende OCR Verarbeitung um die Erkennungsrate und Lesbarkeit zu erhöhen, Damit lassen sich auch leere Seiten, schwarze Ränder, Lochungen, Linien und Verunreinigungen entfernen.
Dafür haben wir jetzt eine eigene Komponenten entwickelt um die Funktionalität einfach und schnell in unsere bestehende bzw. in neu zu entwickelnde Anwendungen zu integrieren.
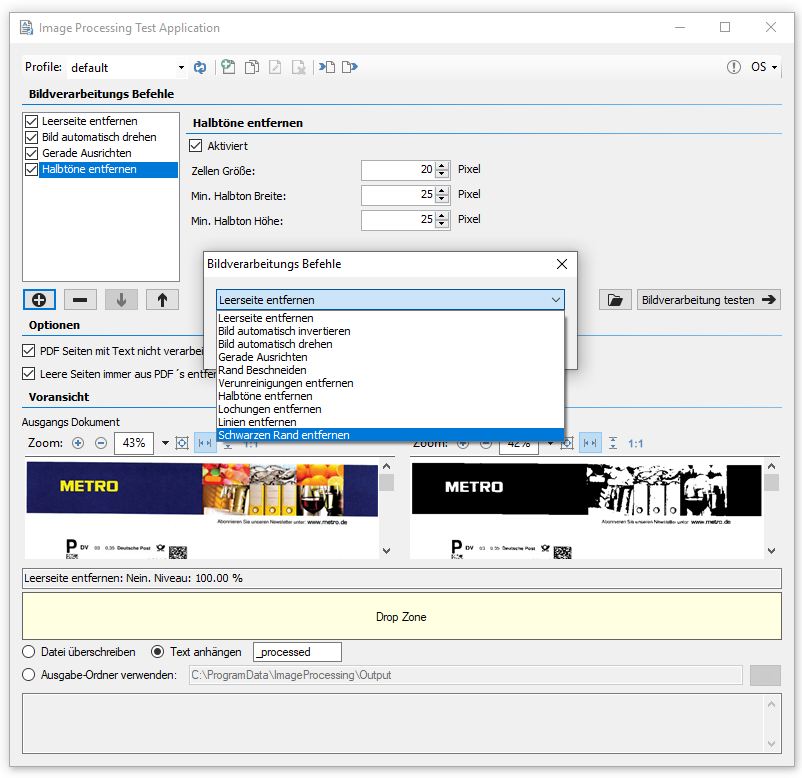
Bildverarbeitungs Funktionen:
- Mehrere Funktionen können in einer vorgegebenen Reihenfolge hintereinander ausgeführt werden.
- Die ausgewählten Funktionen, deren Parameter und Verarbeitungsfolge werden über Profile verwaltet.
- Profilfunktionen: Neu, Kopieren, Löschen, Umbenennen, In Datei exportieren, Aus Datei importieren.
- Option um PDF-Scans / Seiten nur mit Bildinformation bzw. alle PDF Seiten zu verarbeiten.
- Laden einer Musterseite und Test der Bildverarbeitungsbefehle mit Voransicht der Ausgangs- und Ergebnisdatei.
Einzelfunktionen der Bildverarbeitung:
- Leerseiten erkennen und entfernen.
- Seiten automatisch drehen
- Seiten gerade ausrichten
- Bilder invertieren (schwarz nach weiß)
- Schwarzen Rand entfernen
- Rand beschneiden
- Verunreinigungen entfernen
- Lochungen entfernen
- Linien entfernen
- Farbe / Graustufen nach Schwarz/Weiß konvertieren