PDF Dokumente können auf verschiedene Weise erzeugt werden. PDF´s sind in der Lage in einem Dokument verschiedene Inhalte und Quellen zusammenzufassen. Seiten können aus „normalen“ PDF Inhalten bestehend aus Texten, Bildern, und Vektorgrafiken aufgebaut sein und verfügen üblicherweise bereits über einen Textinhalt der für die Volltext-Indizierung und -Suche verwendet werden kann. Ein PDF Dokument kann jedoch auch gescannte Seiten in Schwarzweiß oder Farbe enthalten. Solche Seiten oder Dokumente müssen einer OCR Erkennung unterzogen werden um die textliche Information für die Indexierung und Suche einzufügen.
Also gibt es bestimmte PDF Dokumente die entweder gar keiner OCR Verarbeitung unterzogen werden sollen, bzw. müssen nur einzelne Seiten oder auch alle verarbeitet werden da diese durch einen Scanvorgang erzeugt wurden.
Im Normalfalls kommen alle diese Arten von PDF Dokumenten in Geschäftsprozessen vor und der Anwender kann gar nicht unterscheiden ob ein Dokument OCR´t werden muss oder nicht – von Außen über den Adobe Reader oder auf dem Drucker betrachtet kann das nicht sofort erkannt und unterschieden werden.
Würde man jetzt generell jedes PDF Dokument / Seite auf die gleiche Art und Weise verarbeiten unabhängig davon wie diese aufgebaut sind und ob eine OCR Verarbeitung Sinn macht oder nicht, gäbe es dabei einige Nachteile:
Dabei wird jede PDF Seite unabhängig vom Aufbau und Inhalt nochmals „gerastert“ also in ein Bild umgewandelt und danach OCR verarbeitet – das ist so wie wenn man das Dokument ausdruckt, nochmals einscannt und dann einer OCR Verarbeitung unterzieht. Man erhält damit aus einer „normalen“ PDF Seite ein Bild mit darunterliegendem per OCR Engine erkanntem Text
- die Qualität ist nicht mehr die gleich wie vorher
- die Dokumente werden dadurch größer
- spezielle PDF Eigenschaften gehen damit verloren (Bookmarks, Links, usw.)
- Verarbeitungszeit und Ressourcen werden verbraucht
- OCR Seitenlizenzen werden unnötig verbraucht
Eine PDF OCR Verarbeitung sollte also „intelligent“ stattfinden damit im Prozess und durch den Anwender nicht mühsam unterschieden und entschieden werden muss ob ein PDF Dokument einer OCR Verarbeitung unterzogen werden muss oder nicht. Noch schwieriger ist dies wenn ein einzelnes PDF Dokument gemischt aus normalen und eingescannten Teilen bestehen.
Deswegen haben wir in AutoOCR eine intelligente OCR Verarbeitung integriert, welche in gleicher Weise sowohl mit der Abbyy als auch mit der iOCR OCR Engine funktioniert. Das kann kann pro Eingangsordner bzw. für die Web-Service Schnittstelle über das OCR Profil gesteuert werden und steht sowohl für die PDF>PDF sowie für die PDF>TXT Verarbeitung zur Verfügung.

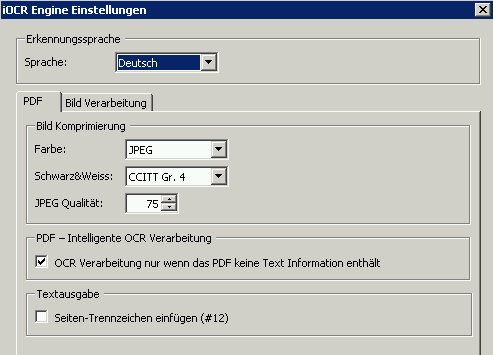
Highlights – Intelligente PDF OCR Verarbeitung:
- funktioniert sowohl für die PDF>PDF sowie für die PDF>TXT Verarbeitung
- für die Abbyy OCR sowie iOCR Engine
- bei der Folder sowie für die Web-Service Verarbeitung
- das PDF Dokument als auch jede einzelne Seite werden analysiert und nur jene Seiten OCR verarbeitet die keinen Text beinhalten – das sind üblicherweise gescannte Seiten die noch nicht OCR verarbeitet wurden.
- bestehende normale PDF Dokumente und Seiten werden unverändert übernommen und nicht verarbeitet
- bereits OCR´te Dokumente und Seiten werden ebenfalls nicht nochmals verarbeitet.
- bei der PDF>TXT Verarbeitung wird der Text aus den normalen PDF Seiten extrahiert und OCR nur auf Seiten ohne Text durchgeführt.
- PDF Funktionen und Bookmarks bleiben erhalten und werden ins Zieldokument übernommen.
- spart Verarbeitungszeit und Abbyy OCR Seitenlizenzen
- die Dateien werden nicht vergrößert
- die Qualität der PDF Seiten bleibt erhalten.
Die „intellligente PDF-OCR Verarbeitung“ findet sich neben AutoOCR auch in allen andern unserer Softwareprodukte die eine OCR Verarbeitung unterstützen z.b. ifresco Profiler, FileConverter, DropOCR, PDFMerge usw.