ifresco Profiler – Demo Plugin – Erfassen von Eingangsrechnungen über Barcode und OCR
Es gibt jetzt einen Demo Plugin für den ifresco Profiler um zu zeigen wie einfach und schnell Eingangsrechnungen im Alfresco ECM/DMS erfasst werden können. So erfasste Eingangsrechnungen können z.B. im Alfresco über die Alfresco-SAP Integration von IT-Novum weiterverarbeitet werden. Wir haben diese Lösung zuletzt in einem Alfresco-Webinar (nächster Termin 8.10.2013) gemeinsam mit IT-Novum und Alfresco präsentiert.
Funktionen Demo Plugin – Eingangsrechnugserfassung:
- Erfassen von Eingangsrechnungen über Scan, PDF-Druckertreiber, Folder, Drag&Drop (TIFF, PDF)
- Manuelles Teilen von Dokumentenstapel bzw.
- Barcode Erkennung mit Teilen von Dokumenten sowie Barcode Filterfunktion und Löschen von Barcode Seiten
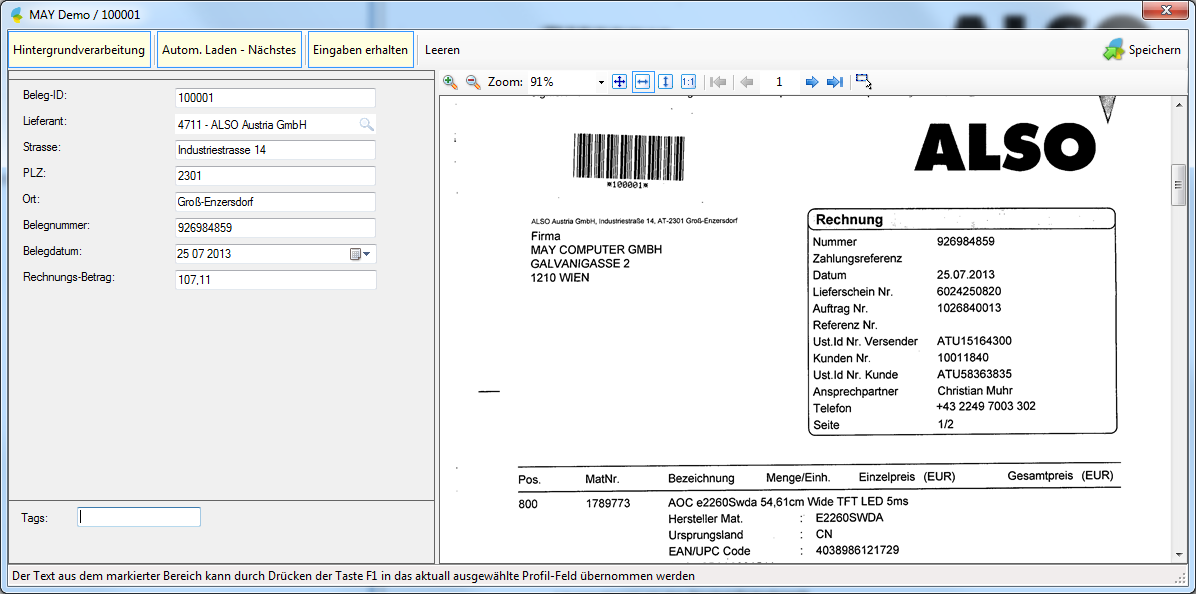
- Erfassen von Metadaten über Profilmaske – Beleg-ID (=Barcode), Lieferant, Straße, PLZ, Ort, Belegnummer, Belegdatum, Rechnungsbetrag – Suche nach Lieferantennummer und Name über externe XLS Tabelle mit Auslesen der damit verknüpften Information – Straße, PLZ, Ort
- Bereichs-OCR um Werte aus dem angezeigten Dokument in ein Feld zu übernehmen.
- Tags abrufen und erfassen
- Batch – Hintergrundverarbeitung für PDF-OCR und Alfresco Upload
- AutoOCR Integration um durchsuchbare PDF Dokumente im Alfresco abzulegen
- Automatische Namensvergabe bzw. Aufbau der Folderstruktur aus den erfassten Metadaten – Nummer, Firma, Belegtyp, Jahr, Belegnummer, Belegdatum
Der Demo Plugin ist als Beispiel anzusehen und kann jederzeit funktionell als auch von Datenmodell an die individuellen Anforderungen angepasst und erweitert werden.
Beschreibung der Installation, Zugangsdaten für den Demoserver sowie Ablauf der Arbeitsschritte >>>
Download – ifresco profiler Basissoftware >>>
Download – ifresco Demo plugin >>>
Download – ifresco Demo plugin Add on >>>




































