FineOCR – kostenloser Commandline Client für den AutoOCR Server
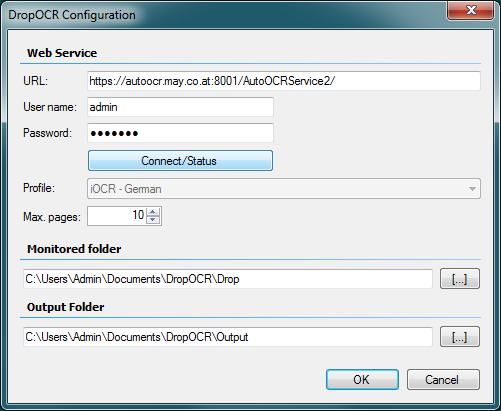
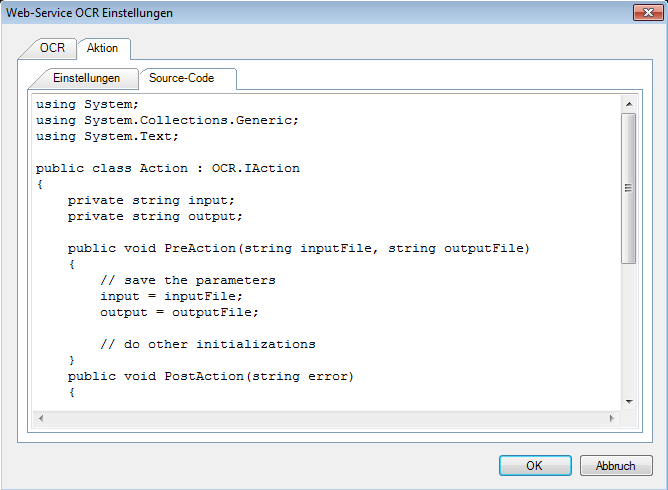
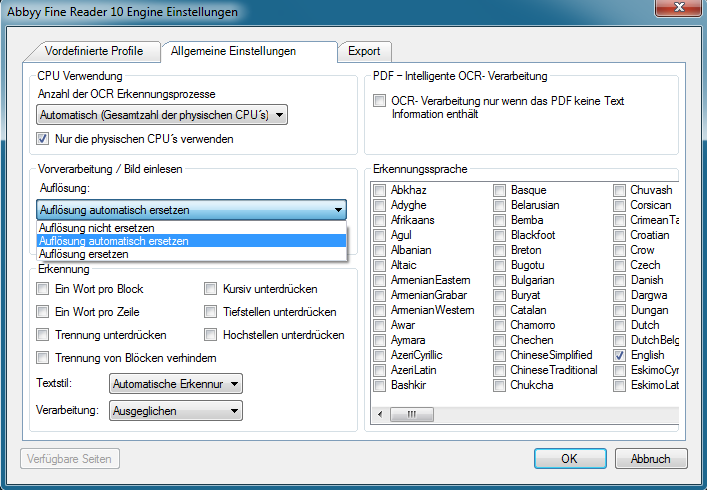
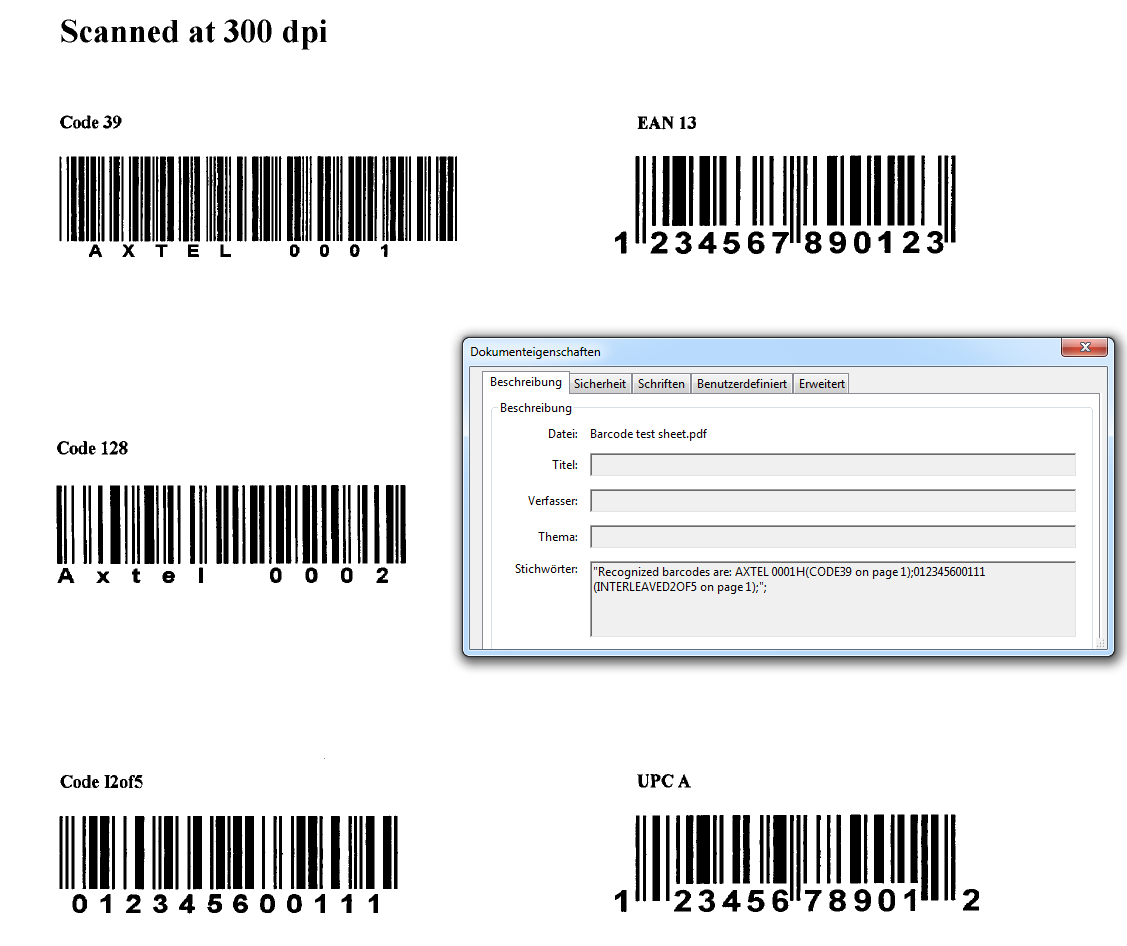
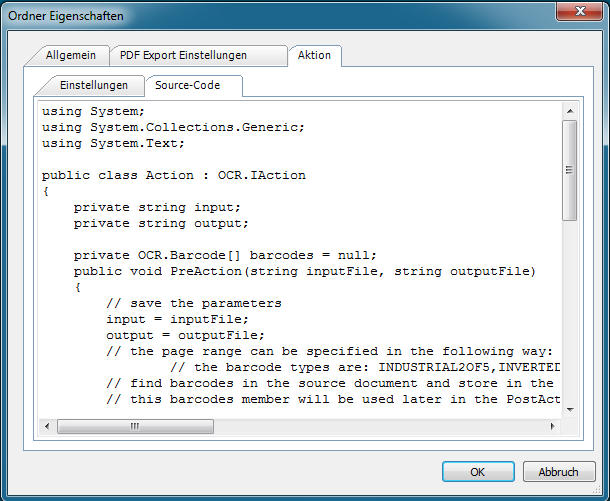
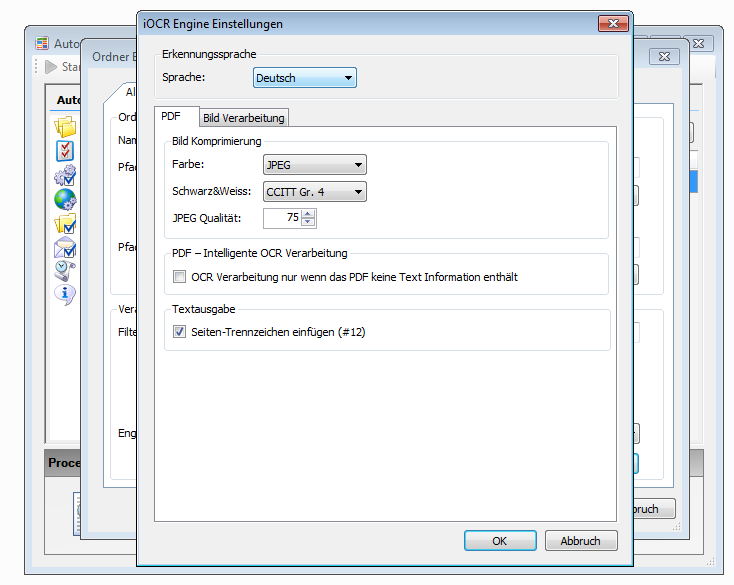
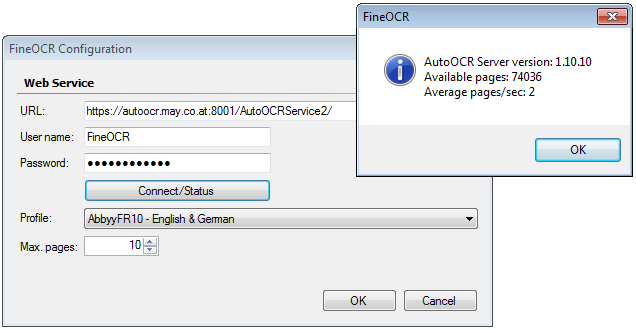
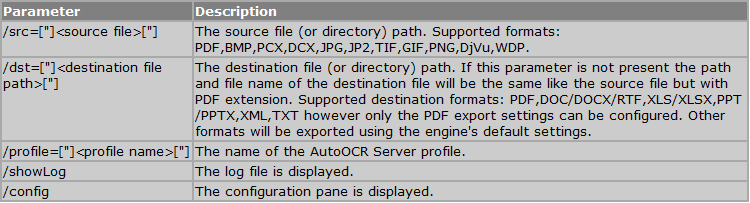
Mit dem kostenlosen AutoOCR Commandline Client „FineOCR“ gibt es jetzt eine weitere Möglichkeit die OCR Funktionen unseres AutoOCR Servers von Clients aus nutzen zu können. Über einen einfachen Commandline Aufruf können PDF und Imagedokumente per Web-Service Schnittstelle von jedem Arbeitsplatz aus über einen zentralen AutoOCR Server – im lokalen Netz bzw. Internet – in durchsuchbare PDF´s oder PDF/A konvertiert werden. Es ist aber auch möglich nur den erkannten Text als Datei geliefert zu bekommen. Durch die Verwendung von OCR-Serverprofilen kann die OCR Engine (Abbyy oder iOCR), Verarbeitungsparameter, bzw. Sprachauswahl gesteuert und ausgewählt werden.
Nach der FineOCR Installation sind bereits die Parameter für unseren gehosteten AutoOCR Testserver voreingestellt so dass OCR Tests sofort ohne weitere Konfiguration durchgeführt werden können.

Voraussetzung:
- AutoOCR Server mit Web-Service Option,
- MS-Windows – 32 oder 64bit OS
Download – FineOCR – Commandline Client für den AutoOCR Server >>>