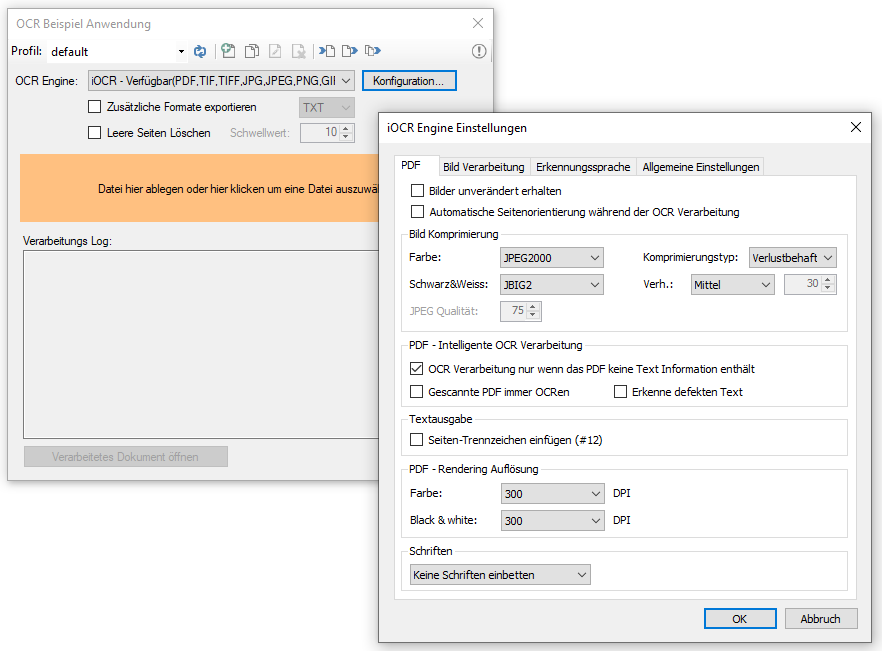
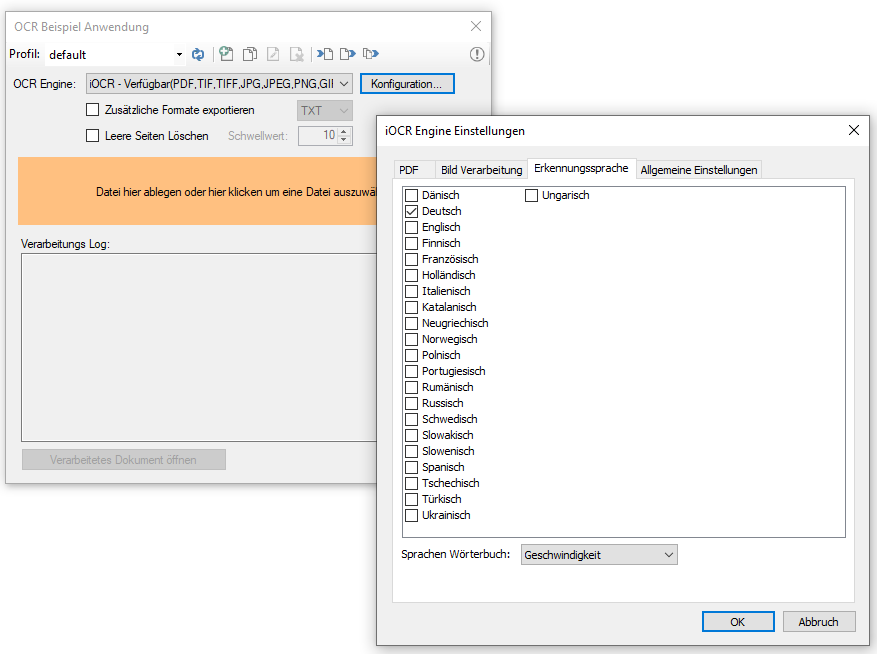
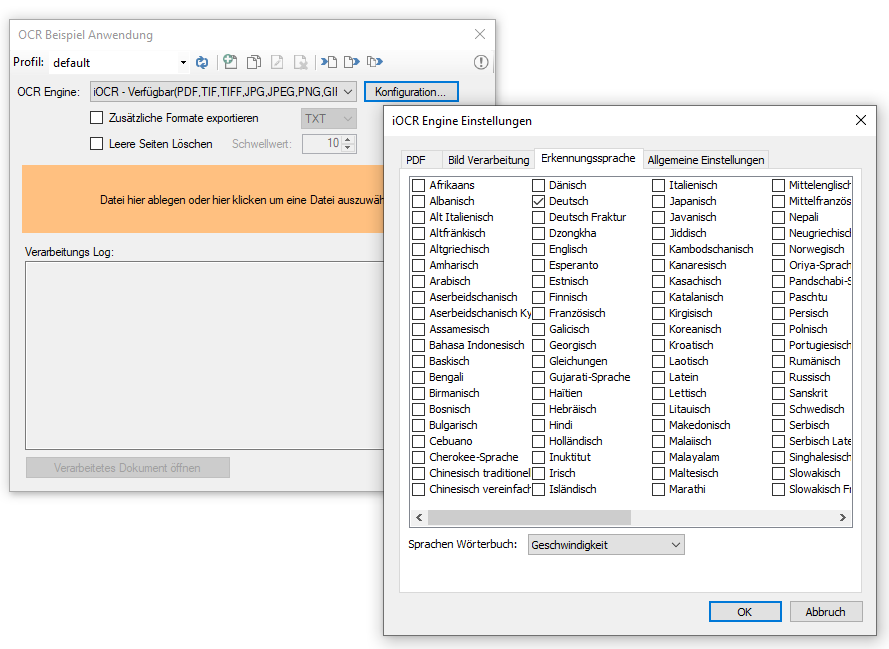
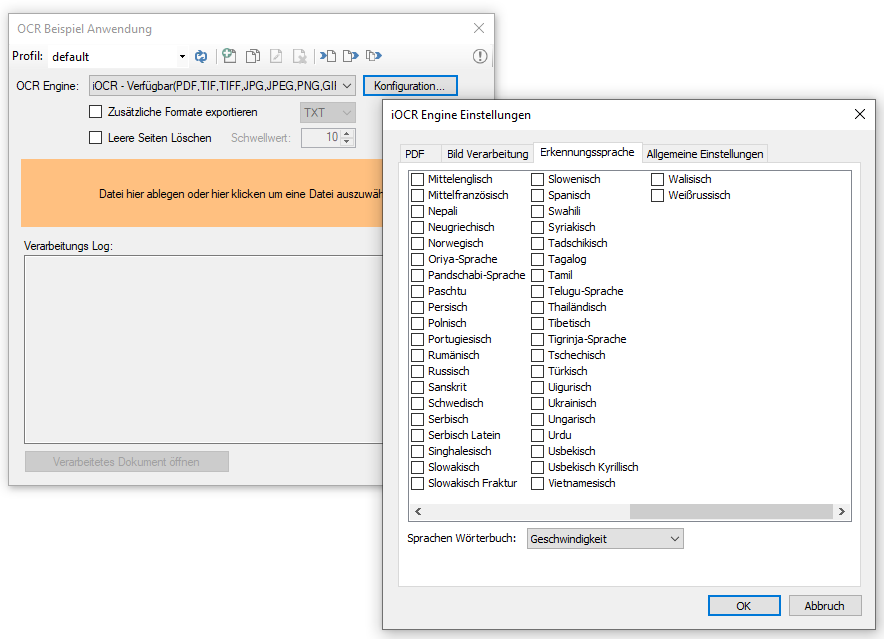
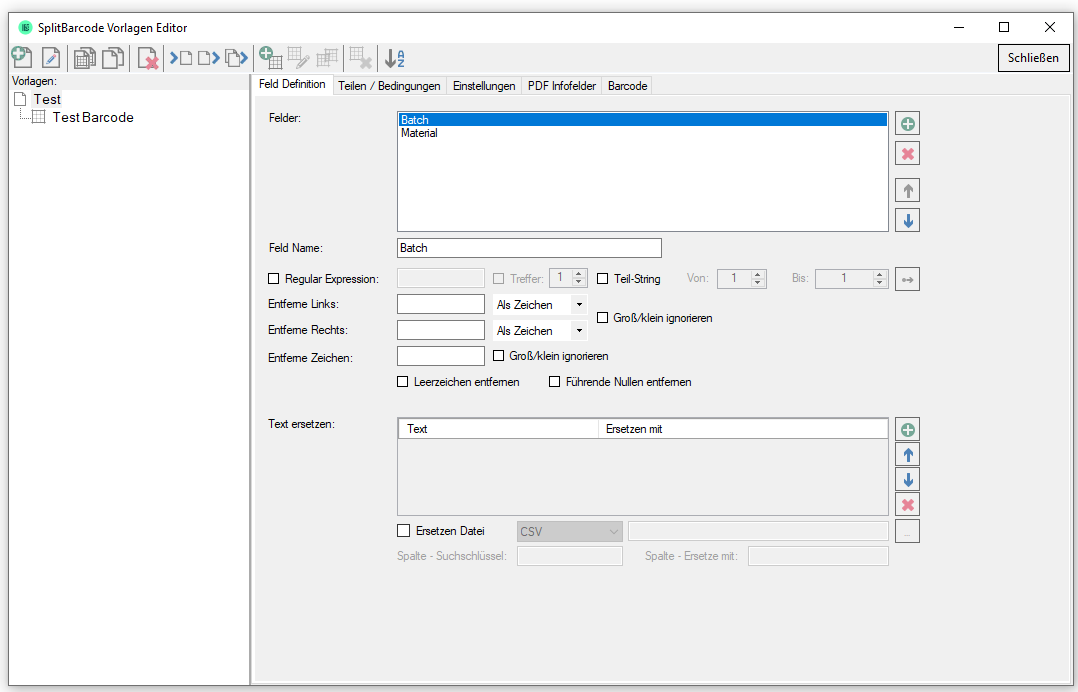
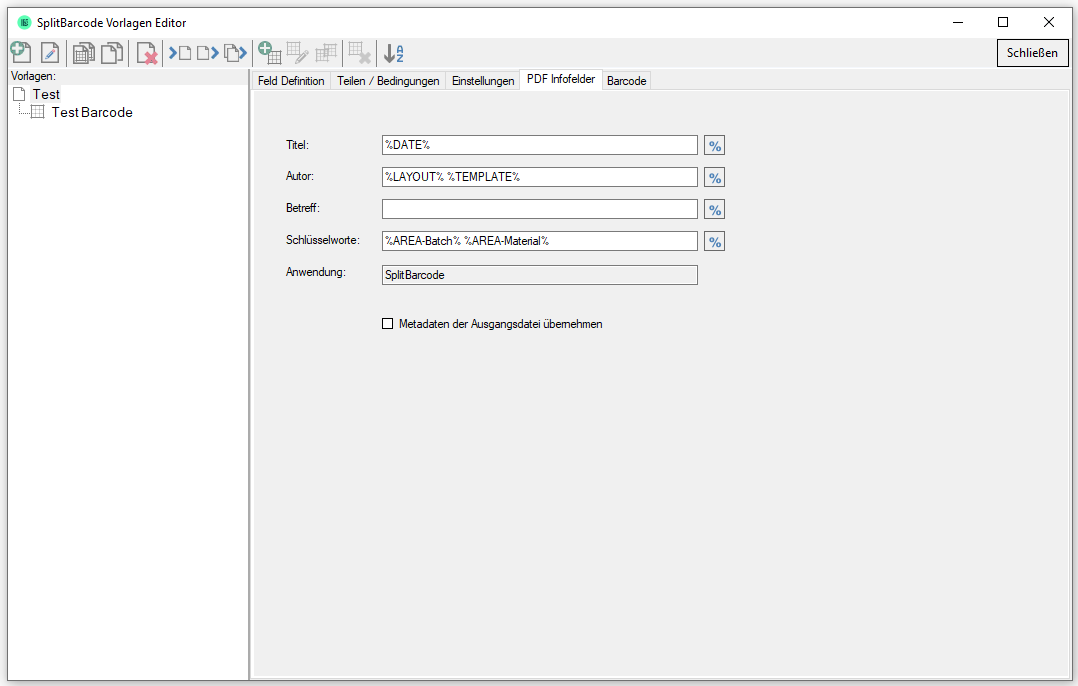
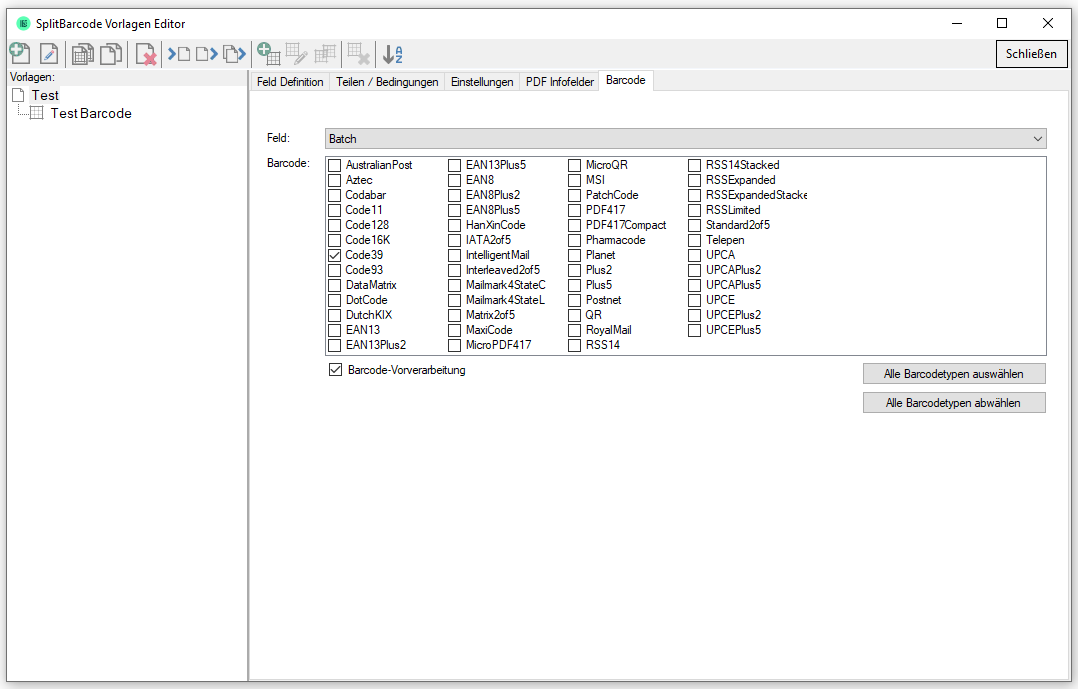
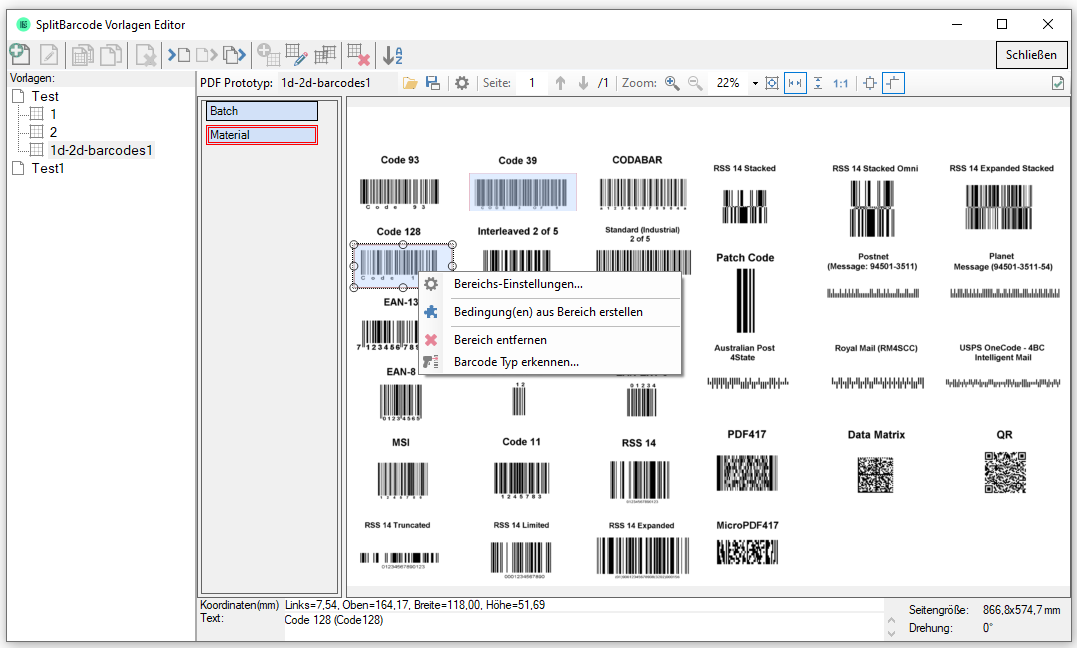
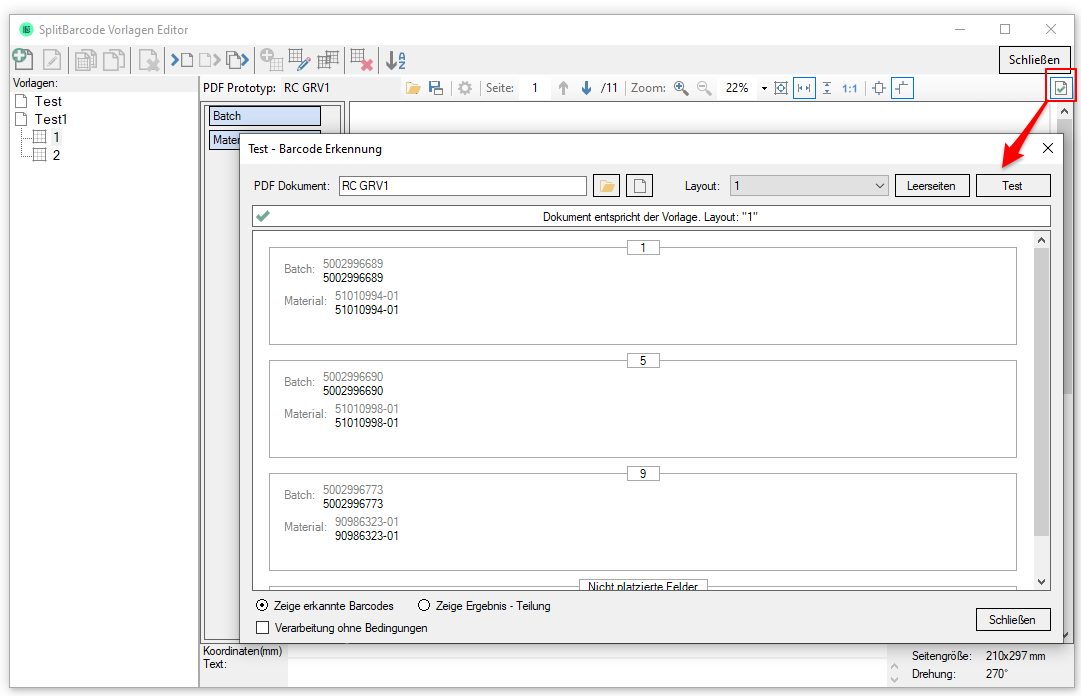
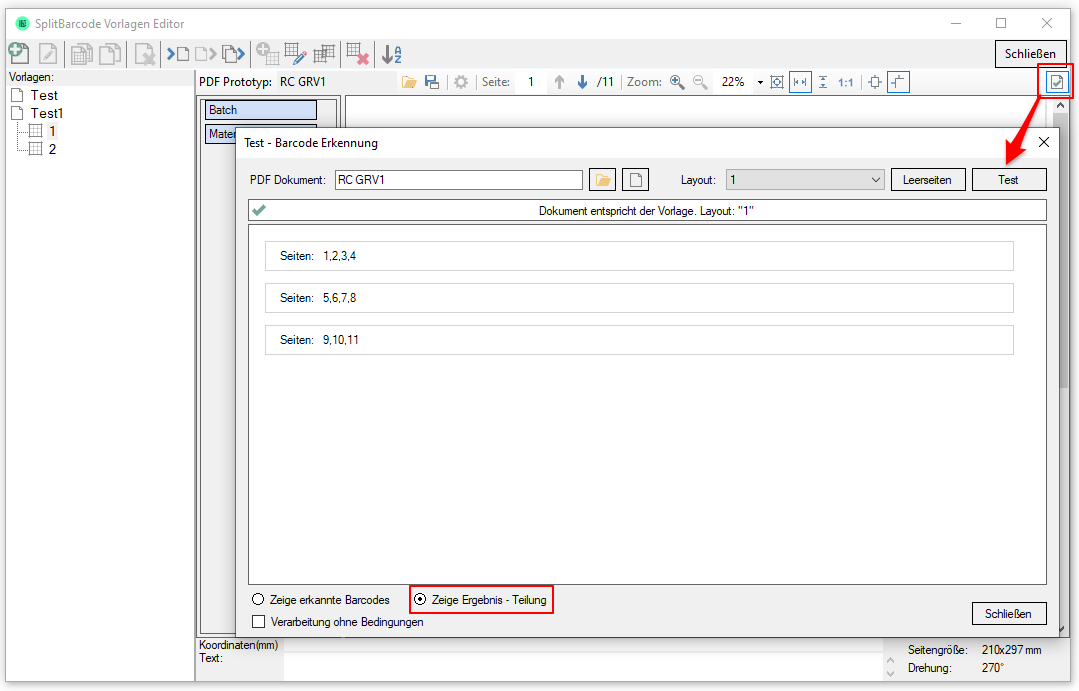
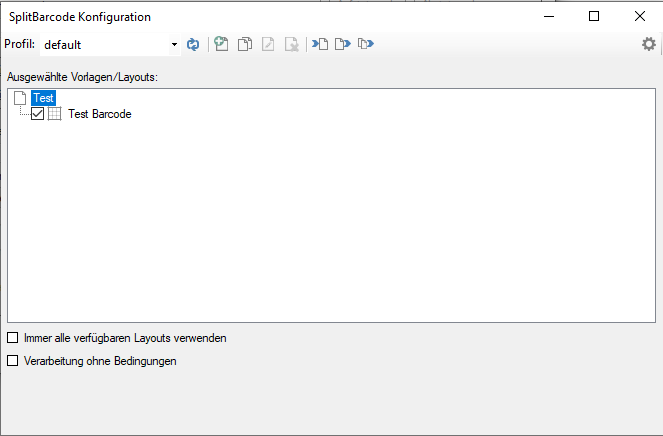
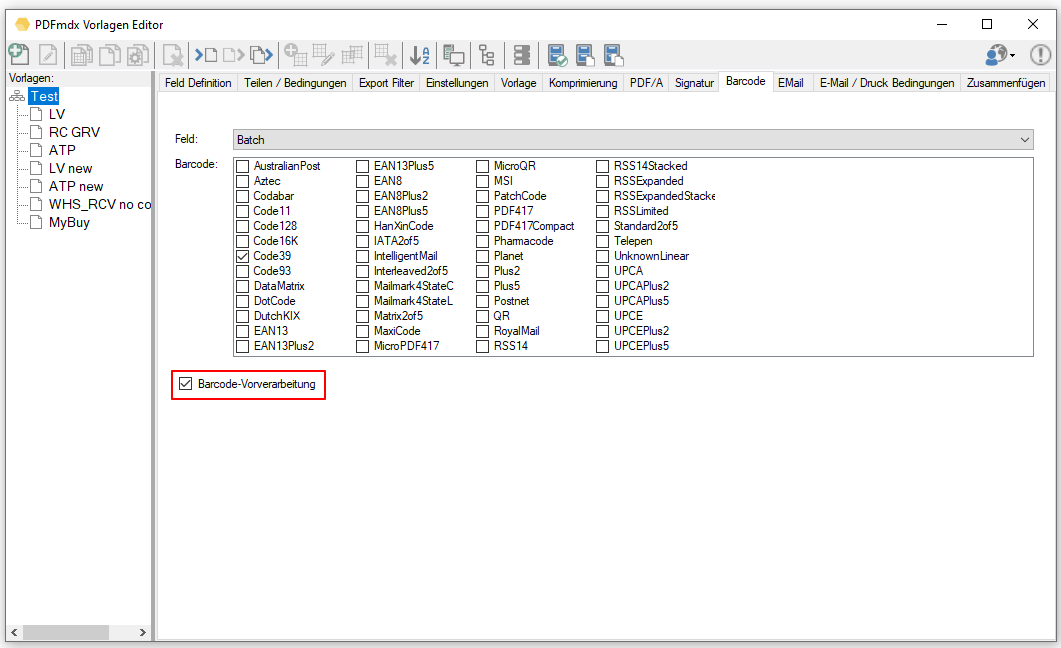
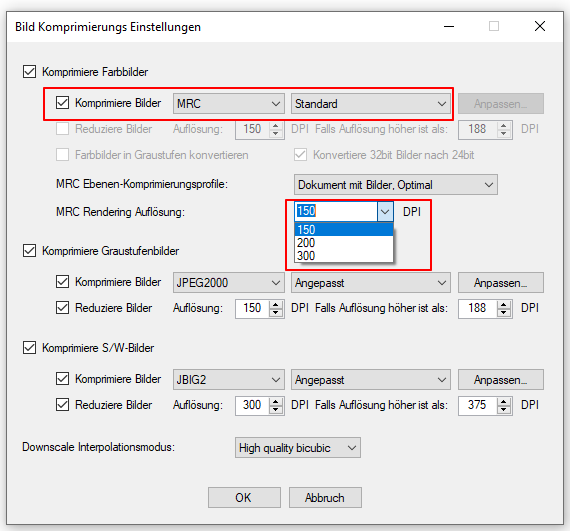
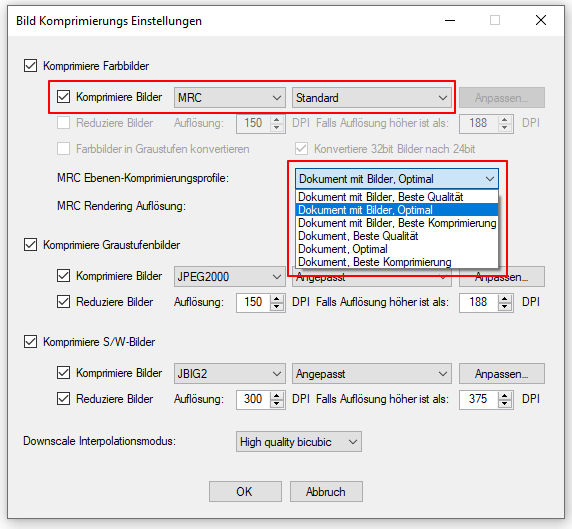
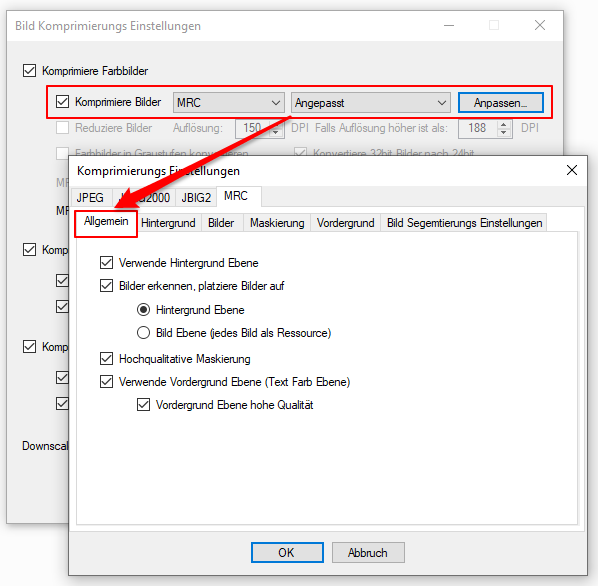
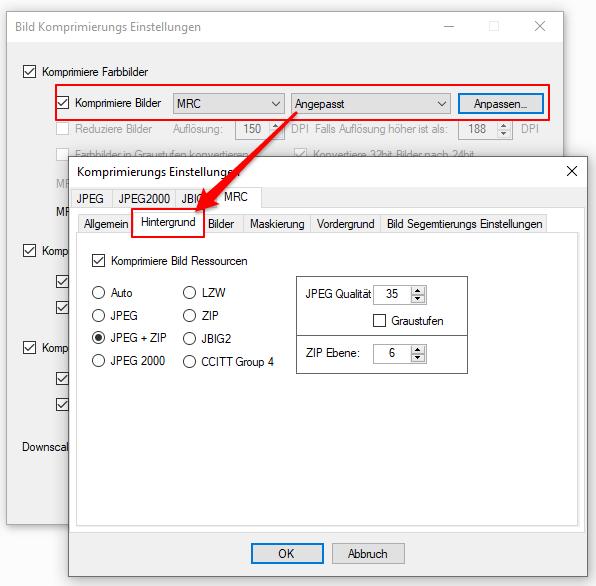
eDocPrintPro – Speichern unter – keine PDF Datei wird angelegt
Falls nach dem „Speichern unter“ Dialog keine PDF Datei am ausgewählten Speicherort unter dem gewünschten Namen angelegt wird, so liegt die Ursache mit hoher Wahrscheinlichkeit daran dass die Microsoft Visual C++ Runtime Komponente auf dem Rechner fehlt oder deinstalliert wurde.
Info : >>>
Download: Microsoft Visual C++ 64bit Runtime