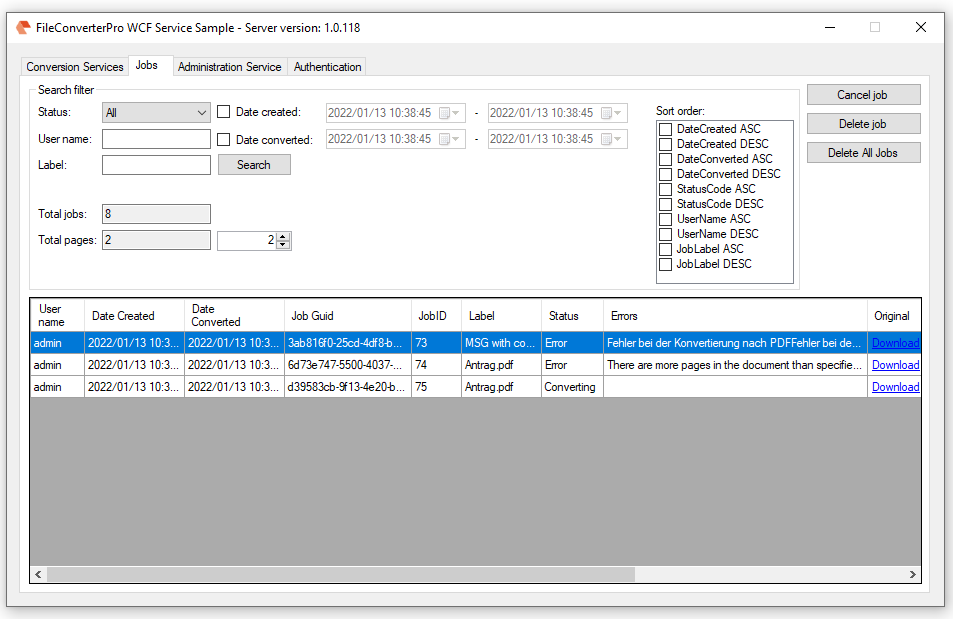
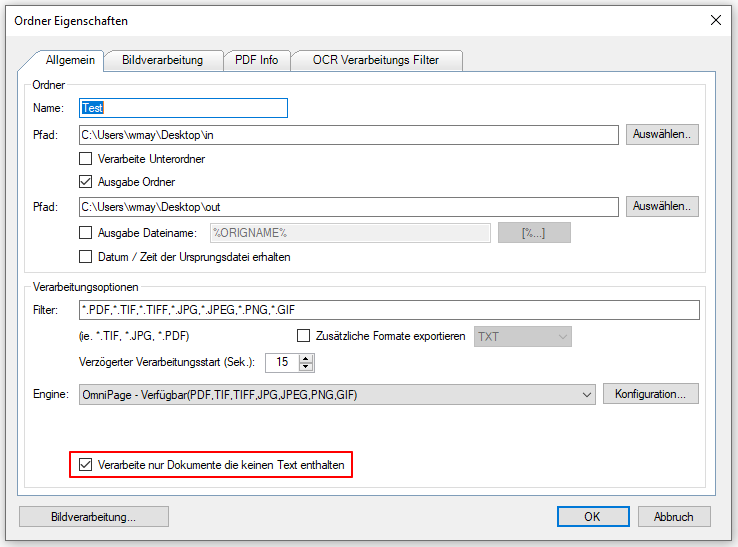
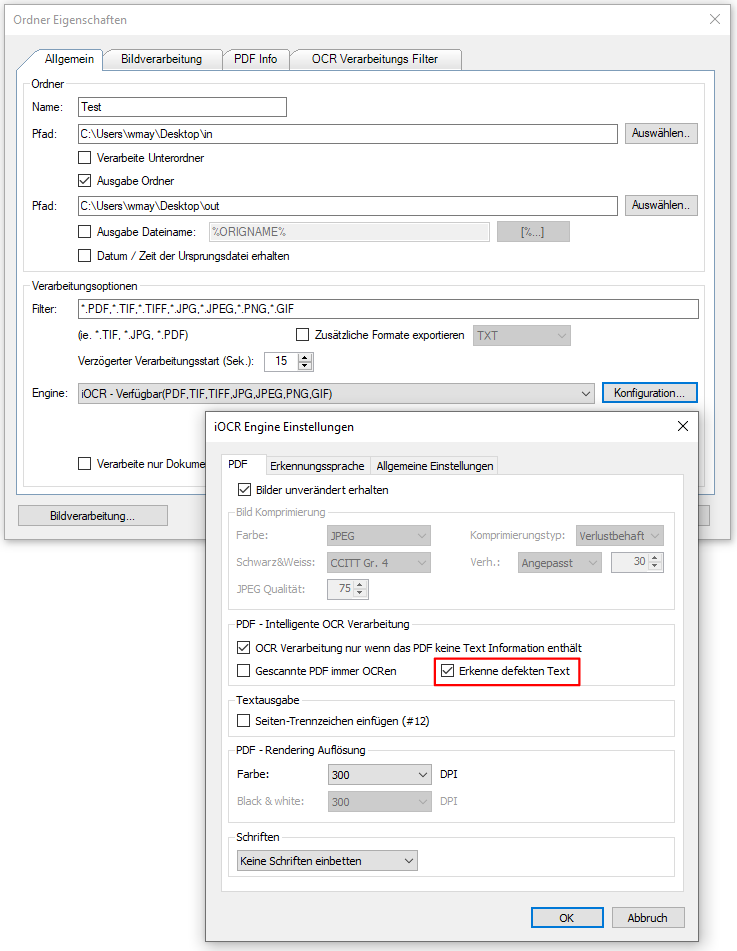
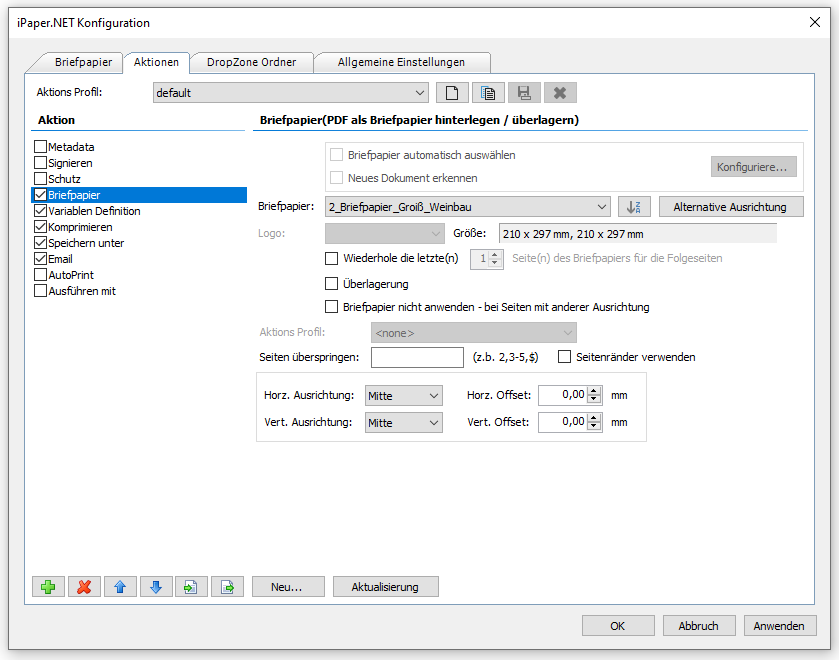
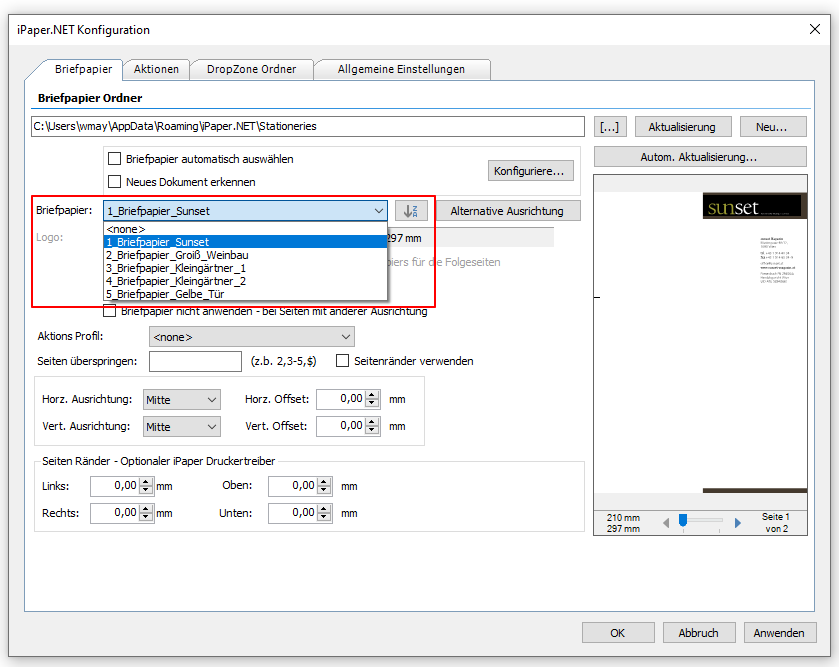
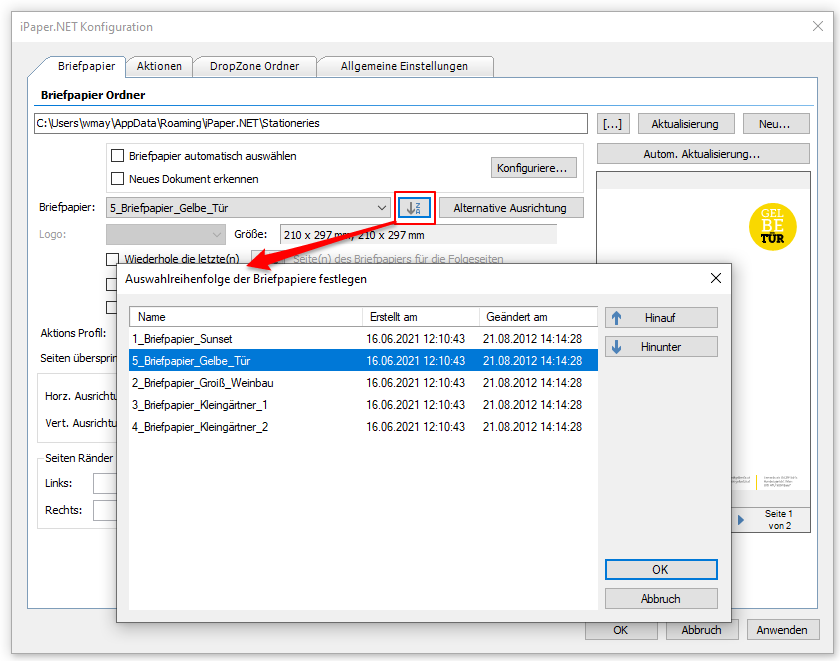
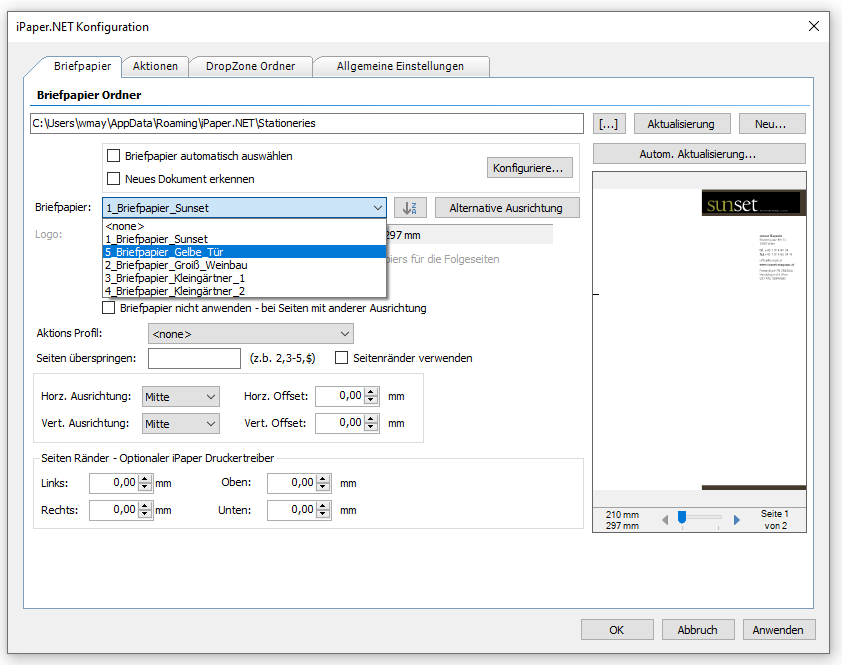
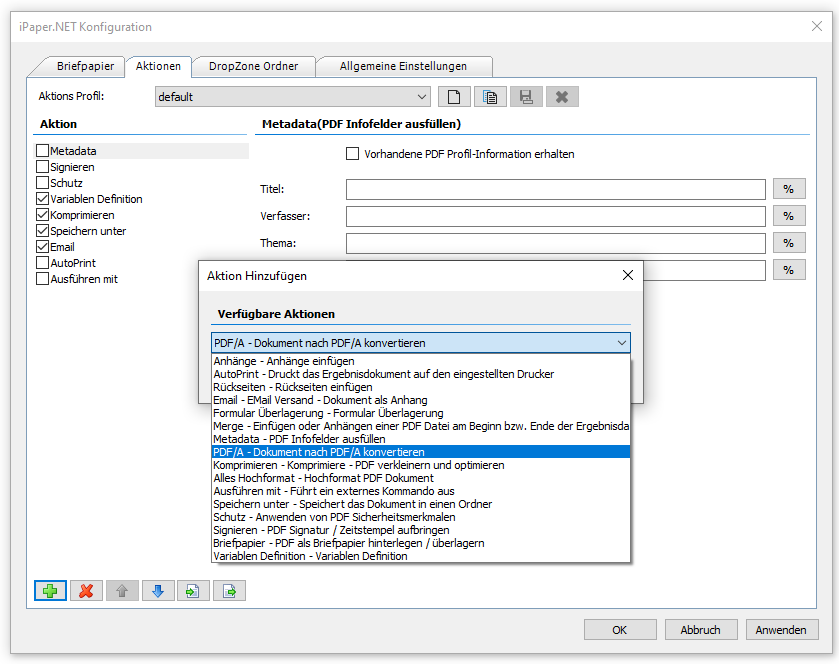
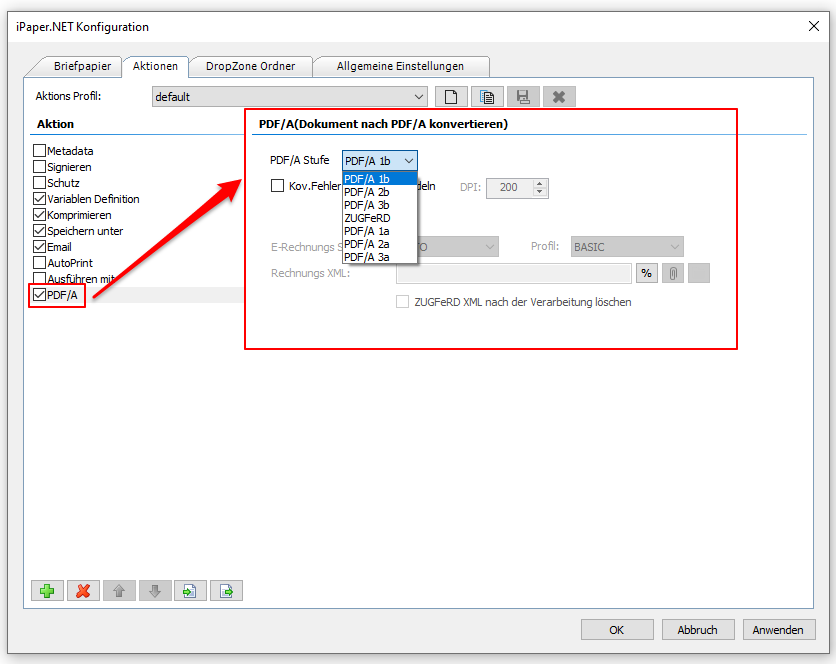
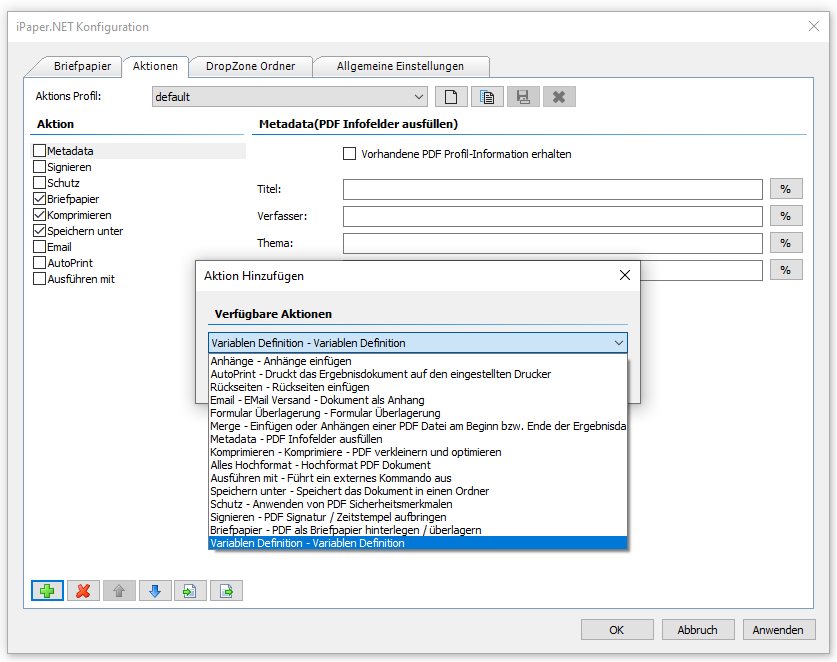
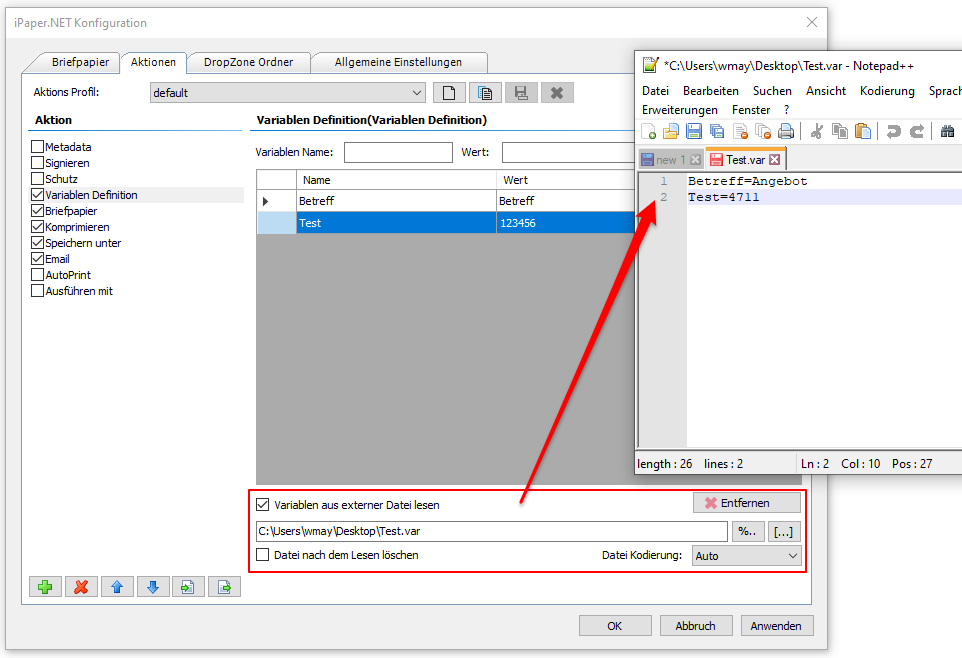
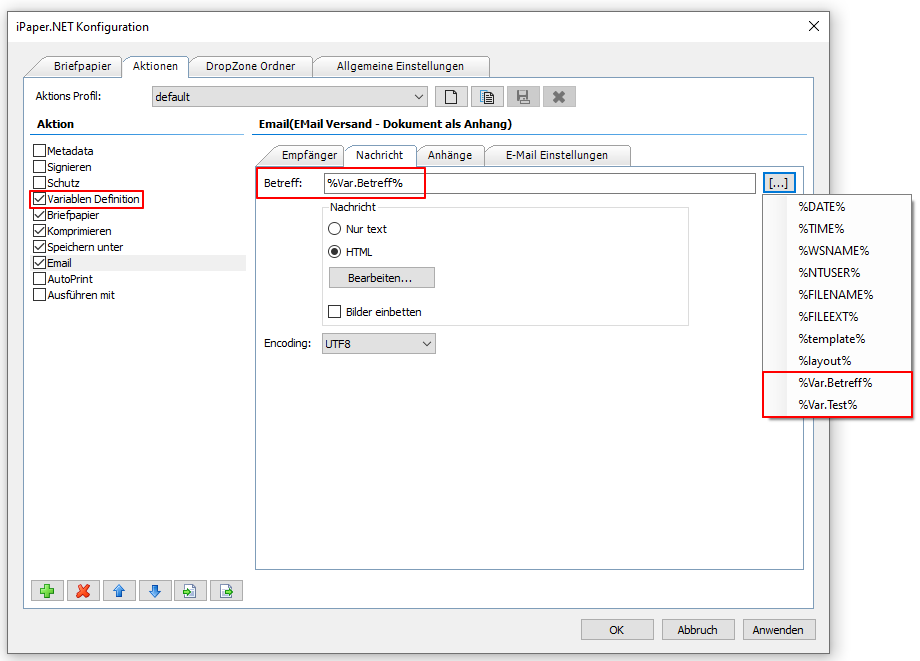
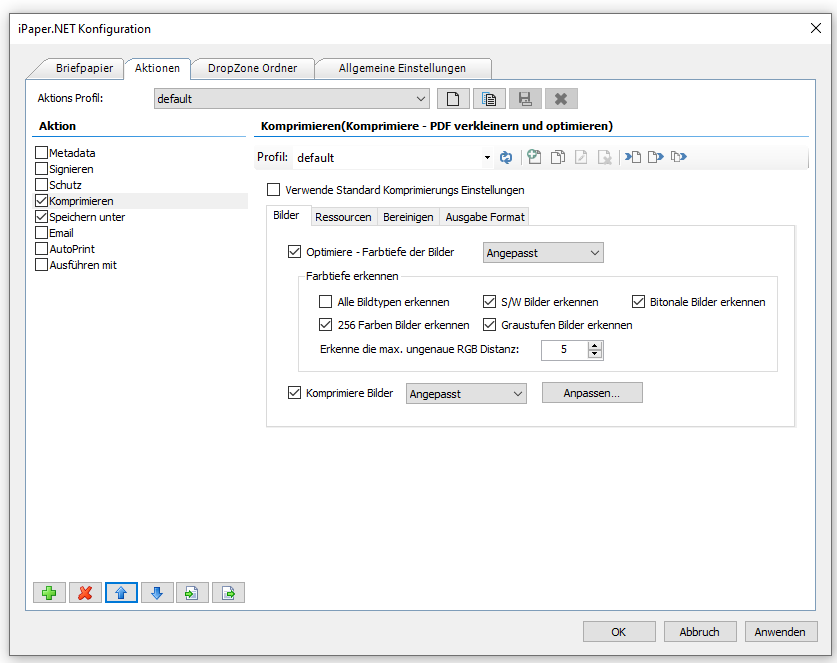
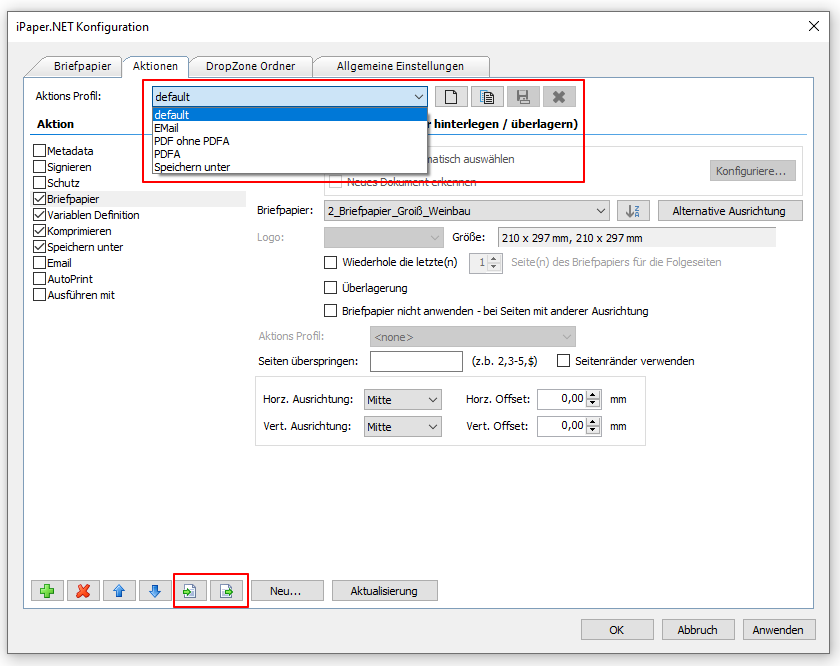
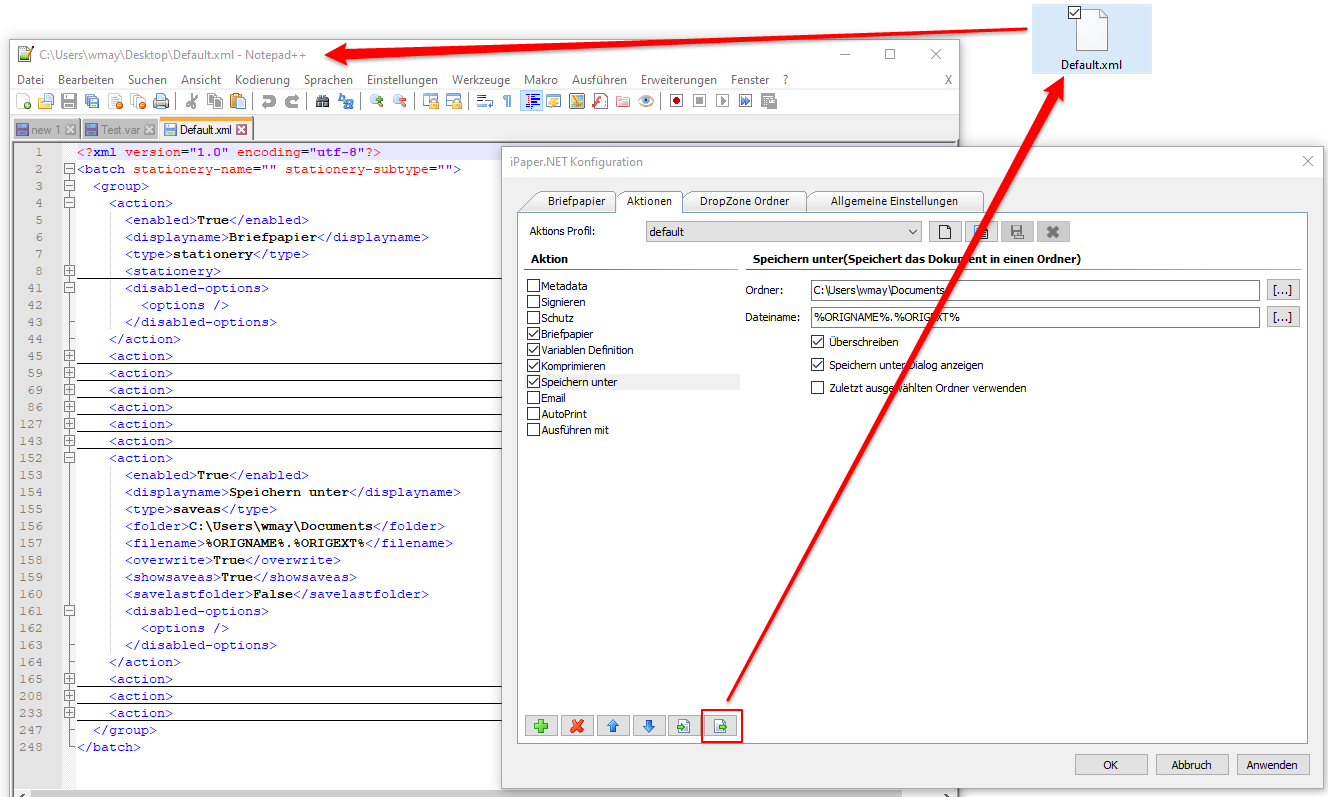
Beispielprojekt Aufruf der PDF2PDFA-CL Kommandozeilenanwendung aus .NET / C#
Wir haben ein C# / .NET Beispielprojekt erstellt um zu zeigen wie die PDF2PDFA-CL Kommandozeilen Anwendung aus einem .NET / C# Programm heraus aufgerufen werden kann.
Funktionen:
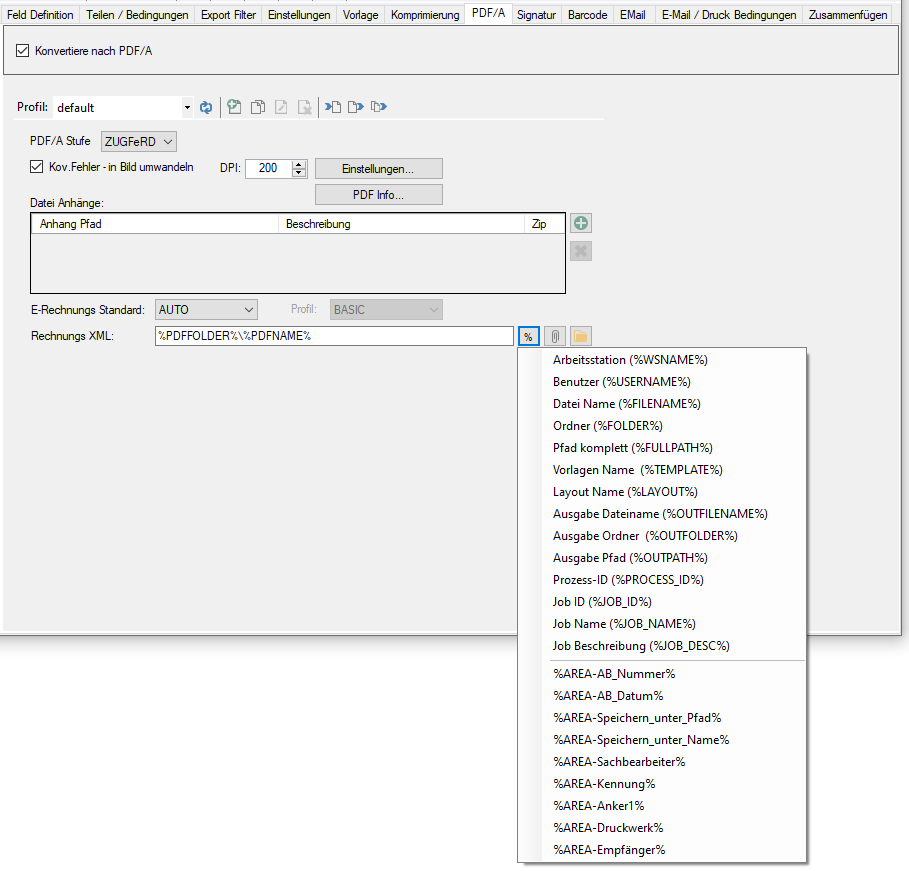
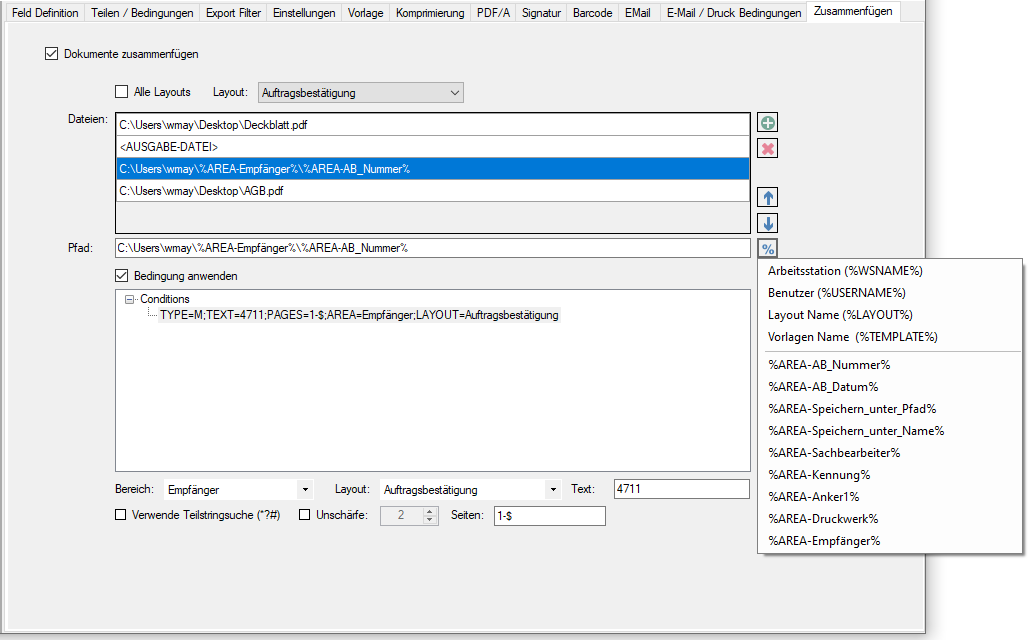
- PDF nach PDF/A Konvertierung mit Hilfe unserer PDF2PDFA-CL Anwendung
- .NET / C# Beispielprojekt im Source Code inkl. ausführbarer Anwendung
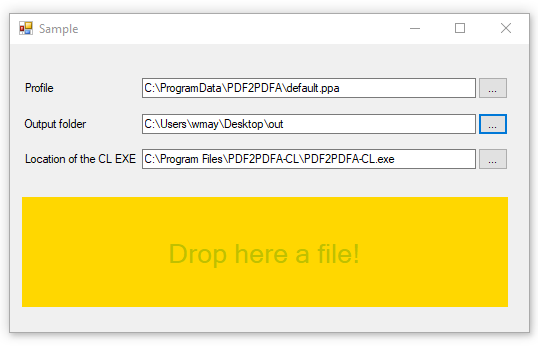
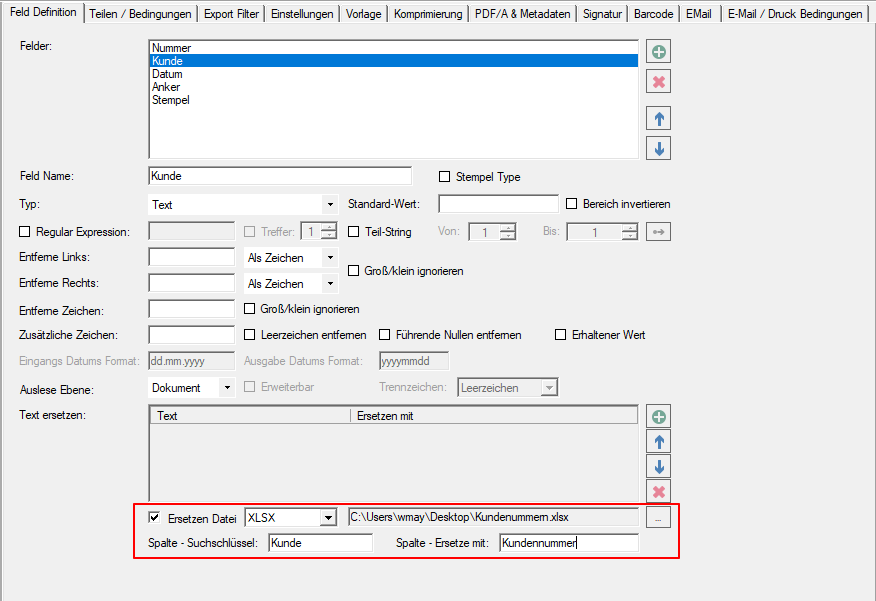
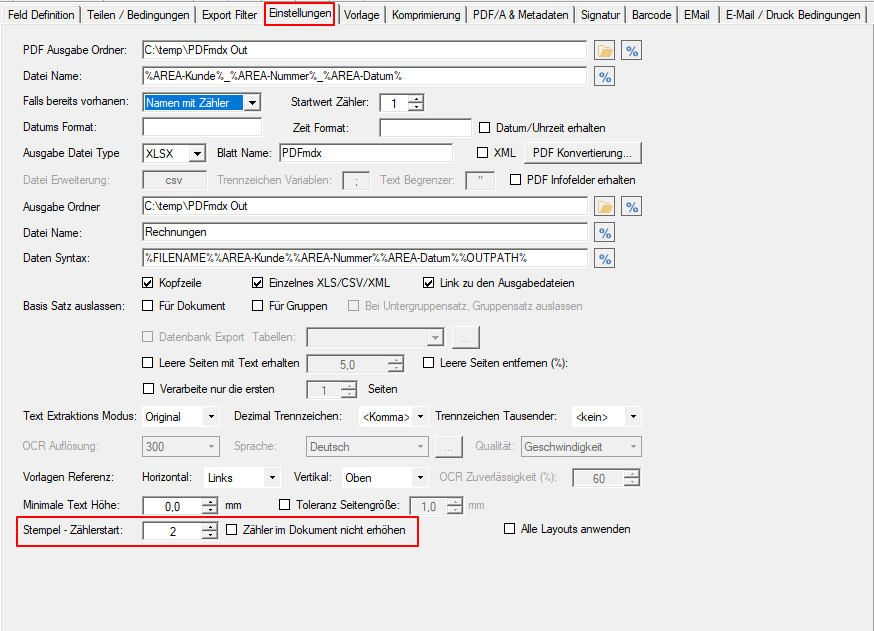
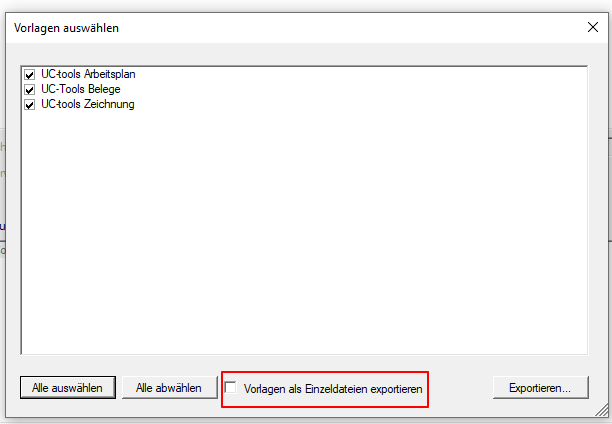
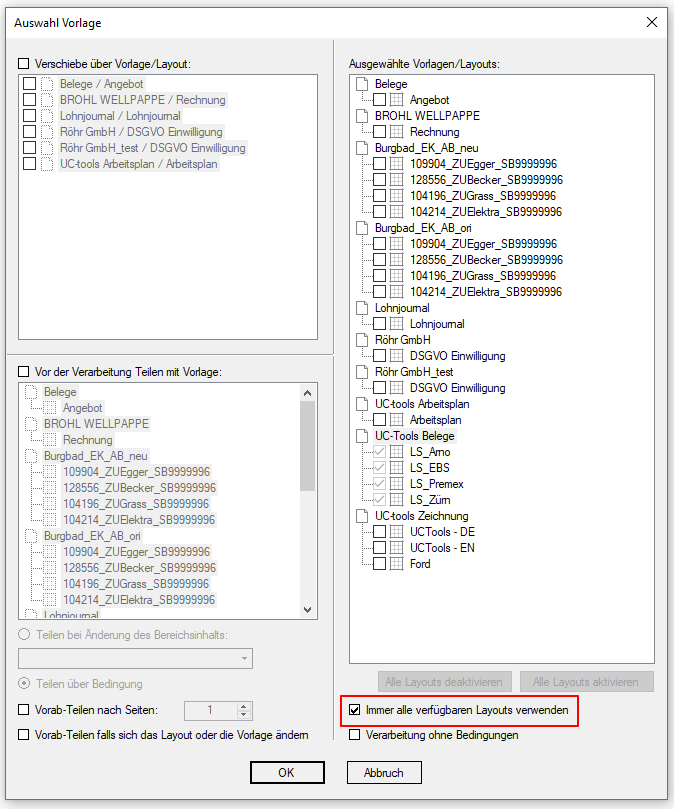
- Auswahl – Konvertierprofildatei (*.ppa) von PDF2PDFA-CL
- Auswahl – Ausgabeordner
- Auswahl – Pfad zur PDF2PDFA-CL EXE
- Start der Verarbeitung durch Drag & Drop einer oder mehrere PDF Dateien in den markierten Drop-Bereich.