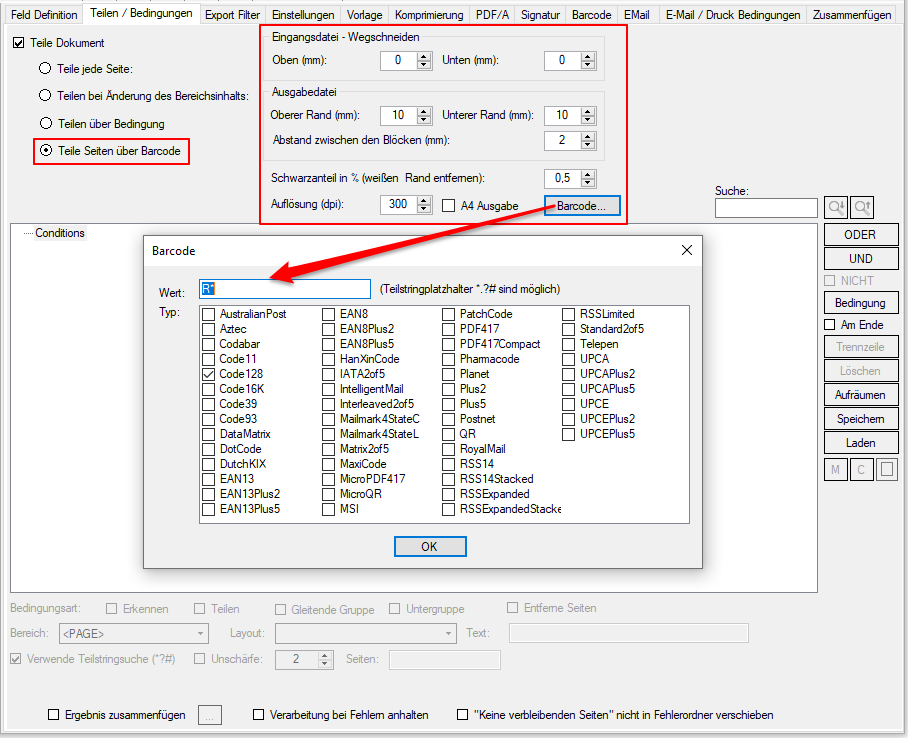
PDFmdx Version 3.24.11
Neuerungen PDFmdx Version 3.24.11:
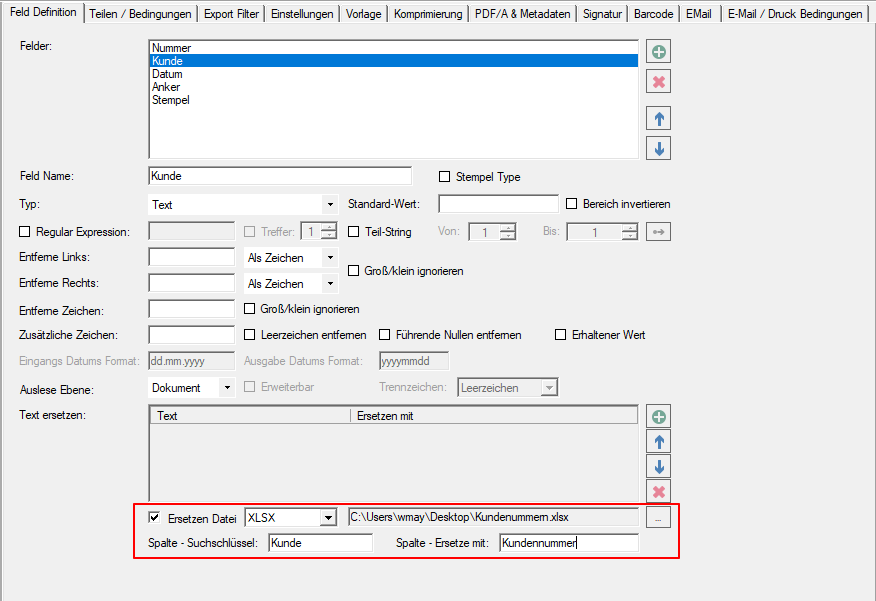
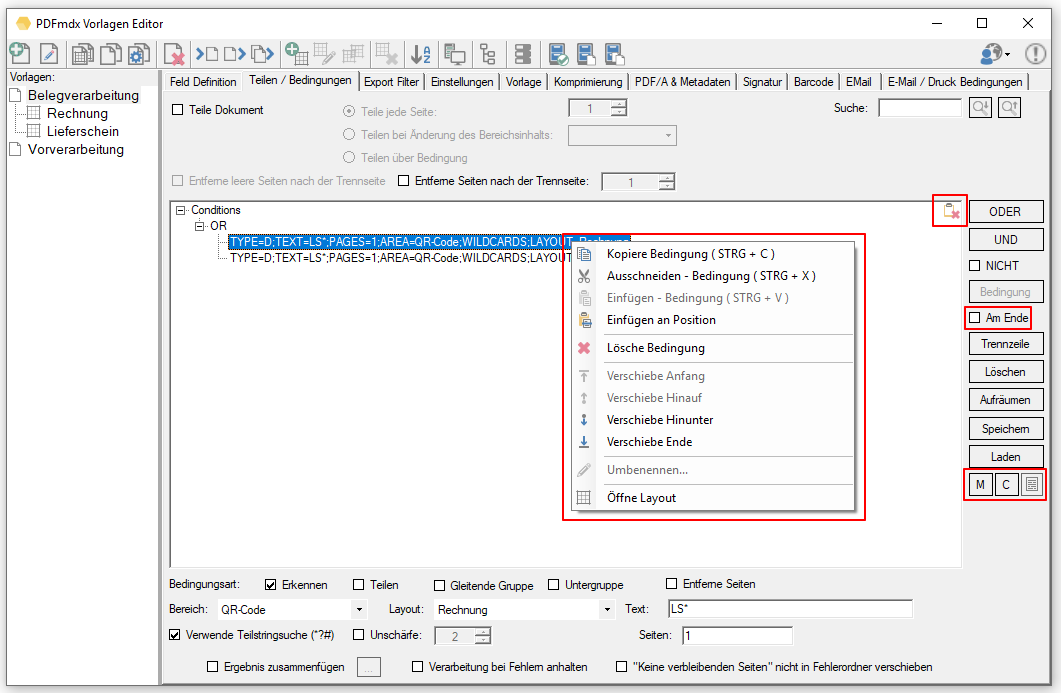
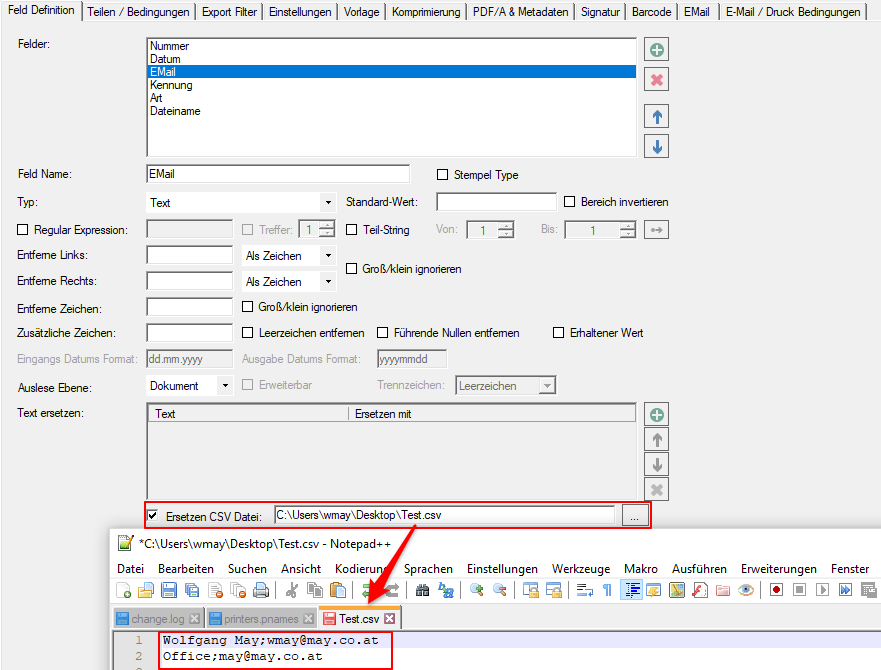
- Textstring ersetzen / externe Tabelle – Teilstring- oder Exakte-Suche: Beim Ersetzen von Variableninhalten wurde der Text bisher nur über Teilstrings ausgeführt. Dabei wurde der Erste in der externen Tabelle gefundene Teilstring für das Ersetzen des Texts verwendet. Diese Funktion wurde erweitert, Alternativ kann auch nach dem exakten String zu gesucht und falls vorhanden, ersetzt werden.
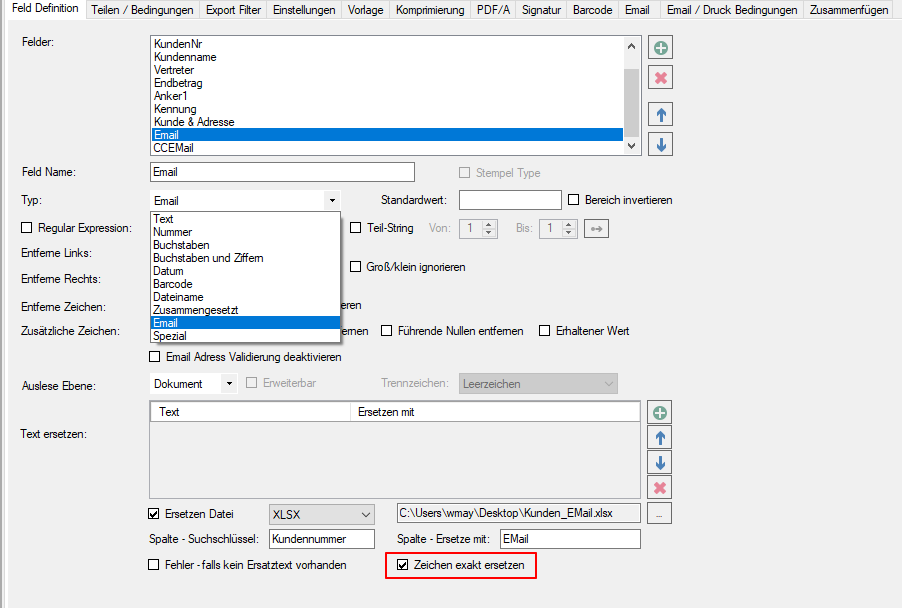
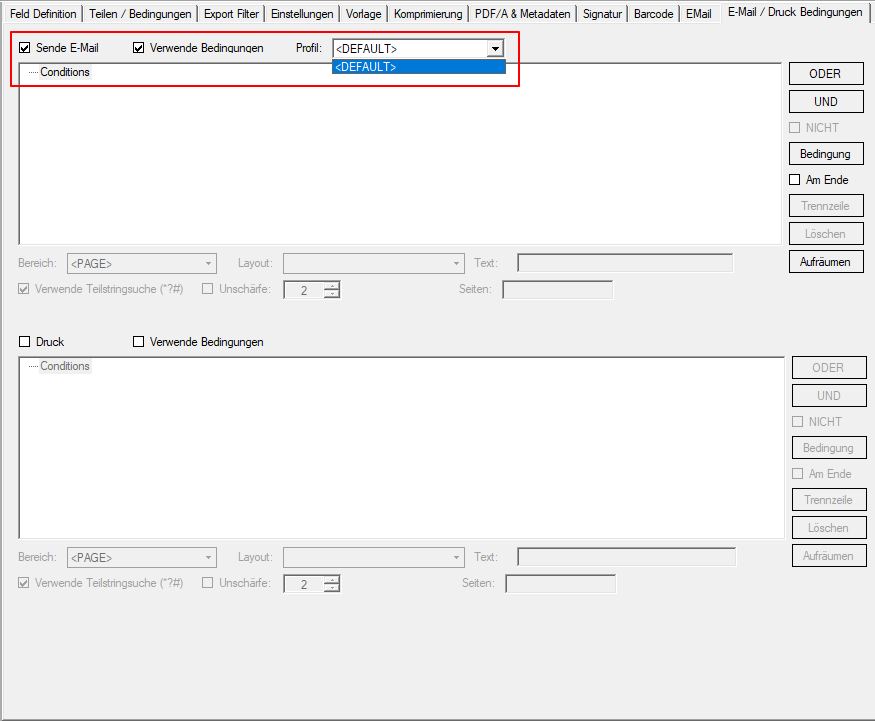
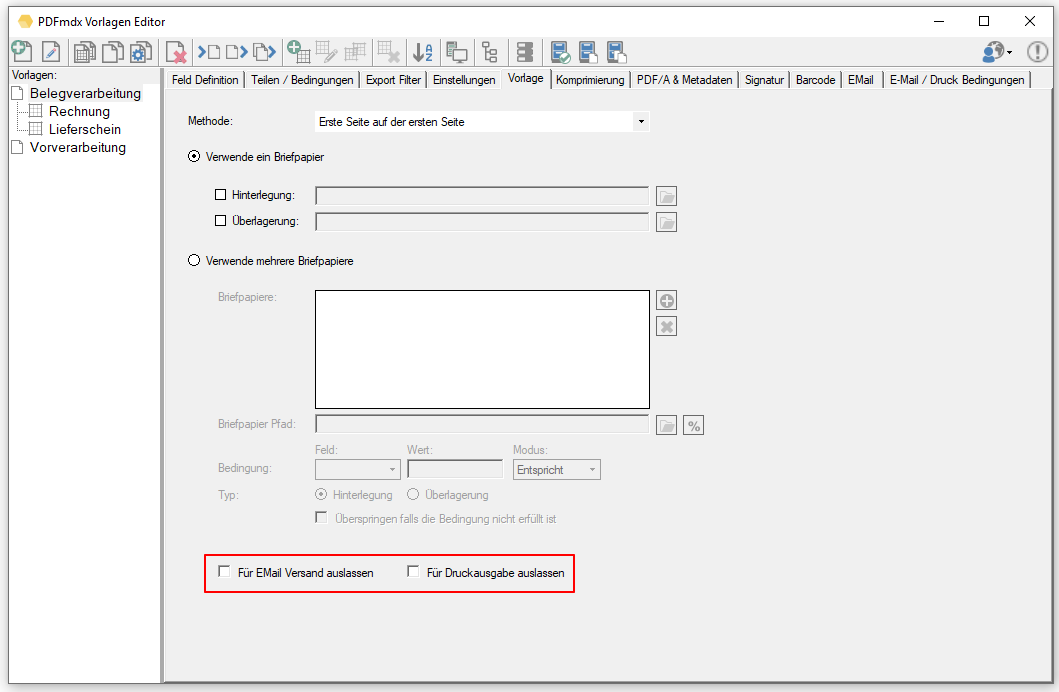
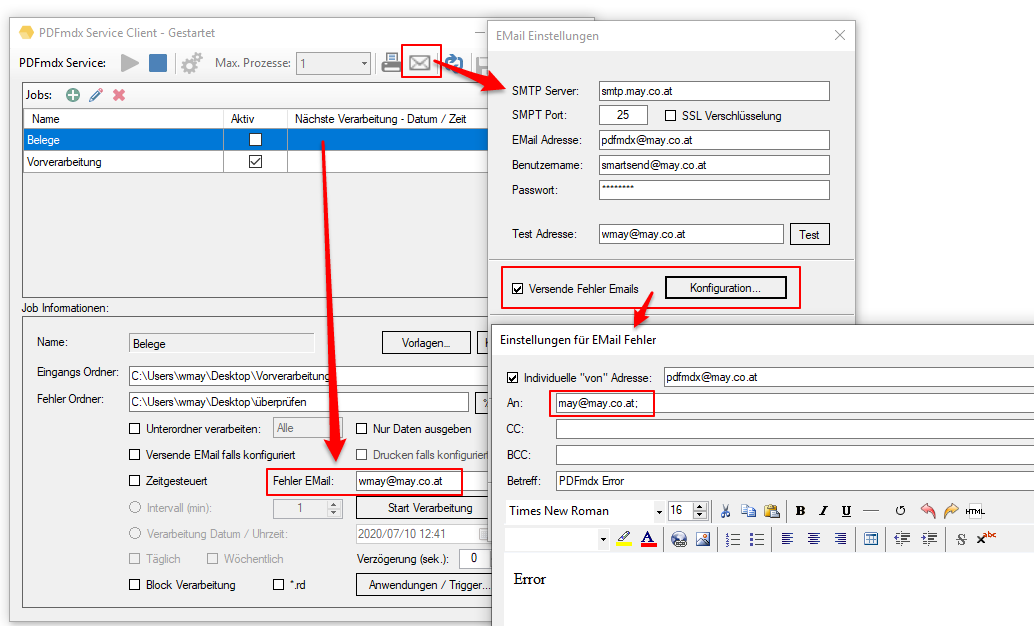
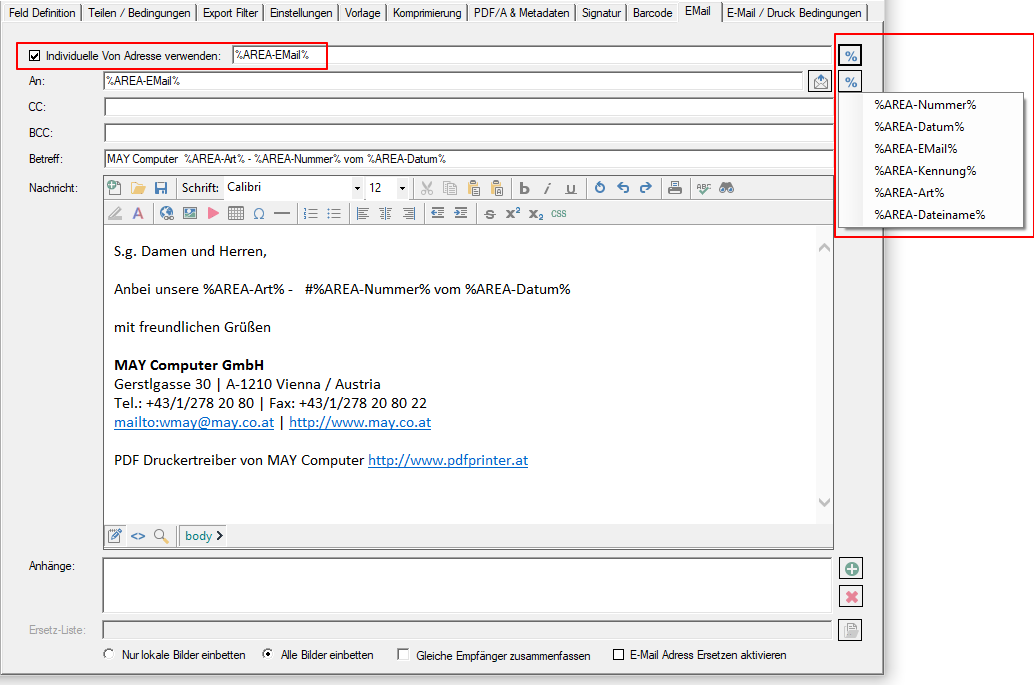
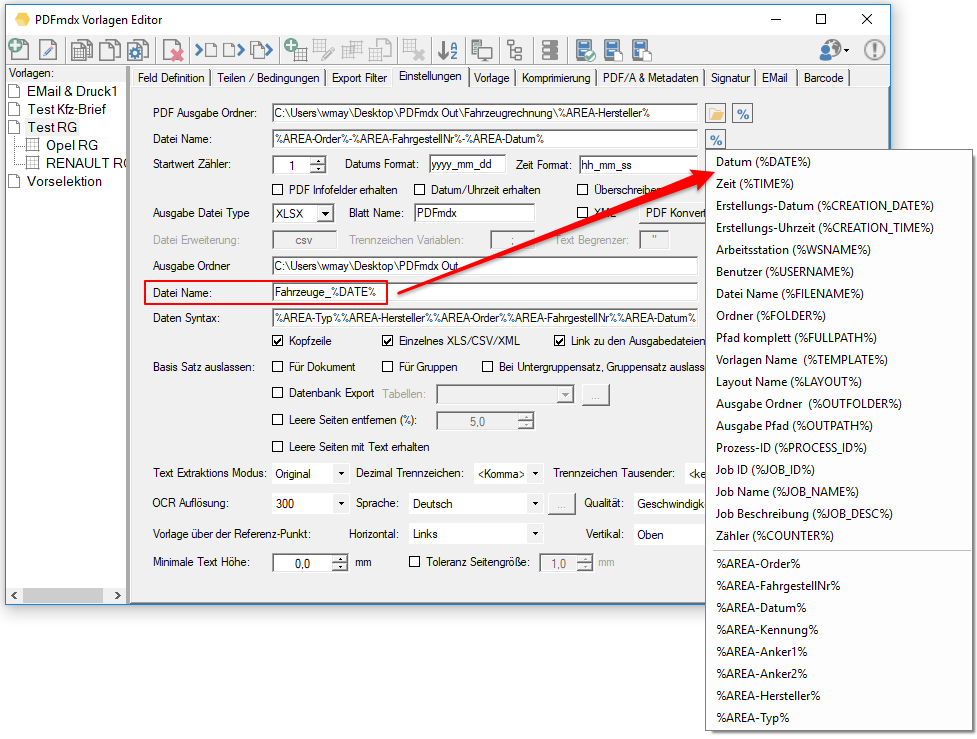
- EMail Adressen – neuer Variablentyp: Die EMail Funktion wurde erweitert. Bisher stand für die EMail Adress Variablen für die Felder – „An“ / „CC“ / „BCC“ nur der Variablentyp „Text“ zur Verfügung. Nun gibt es dafür einen eigenen Variablentyp „EMail“. In den Feldern „An“ / „CC“ / „BCC“ lassen sich jetzt nur mehr Variablen diese Typs auswählen und zuordnen. Anderer Variablentypen stehen in diesen Feldern nicht zur Auswahl. Bestehende PDFmdx EMail Versand Konfigurationen müssen also entsprechende angepaßt werden, ansonsten bleiben diese Felder leer und das EMail kann nicht verschickt werden.
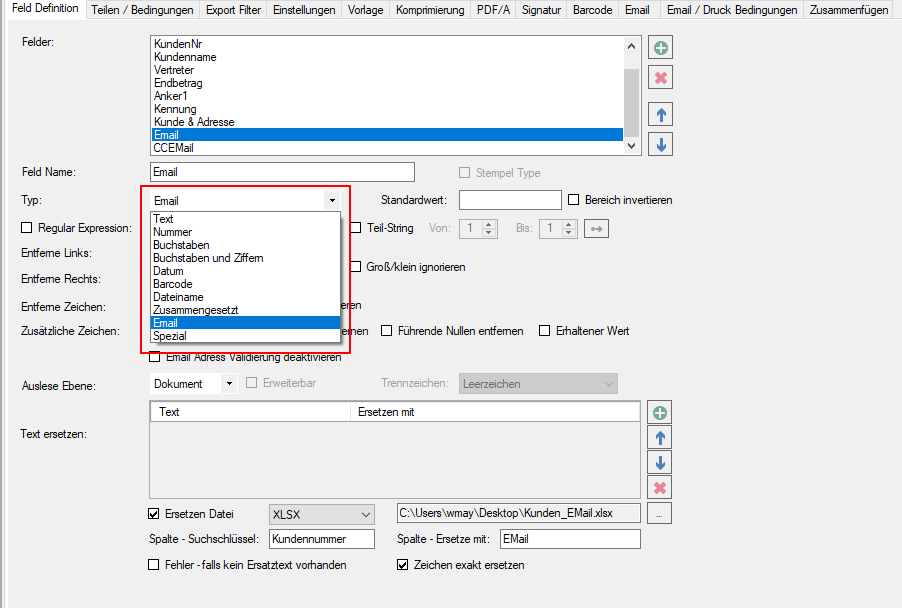
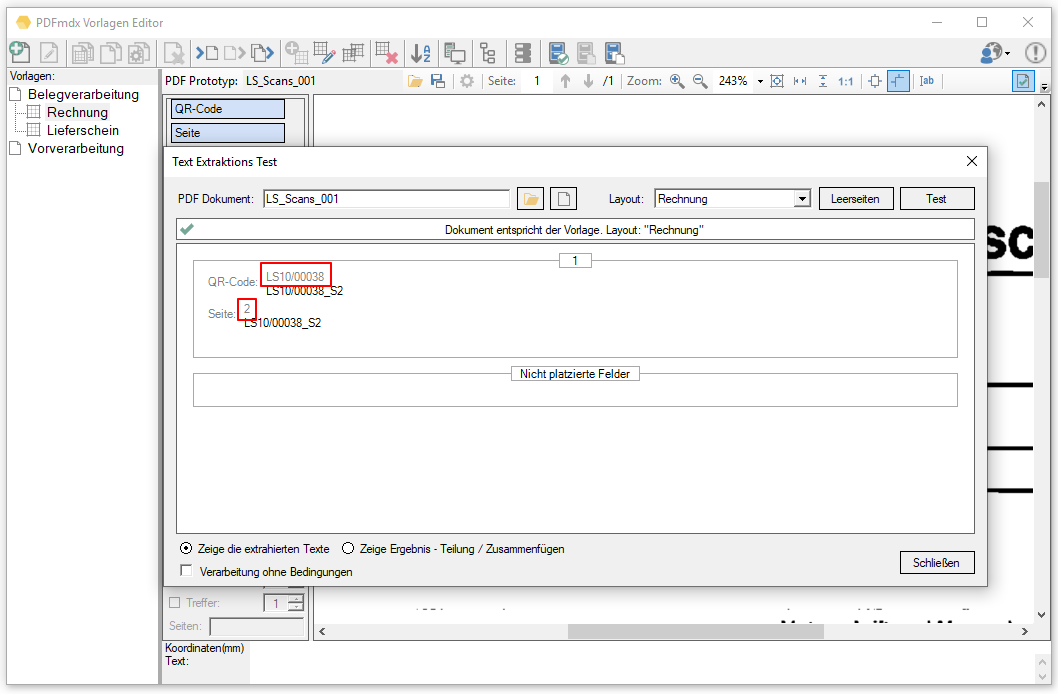
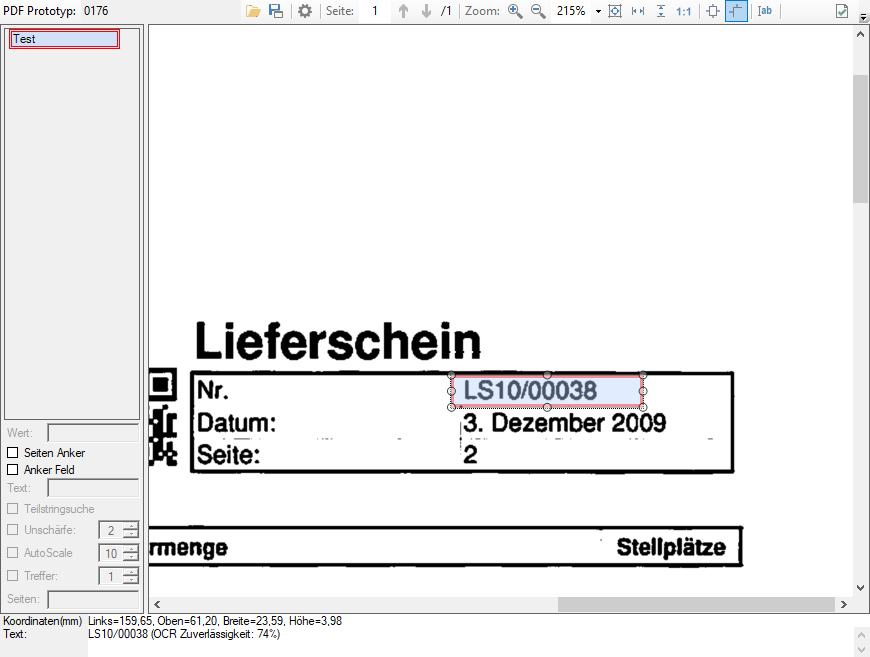
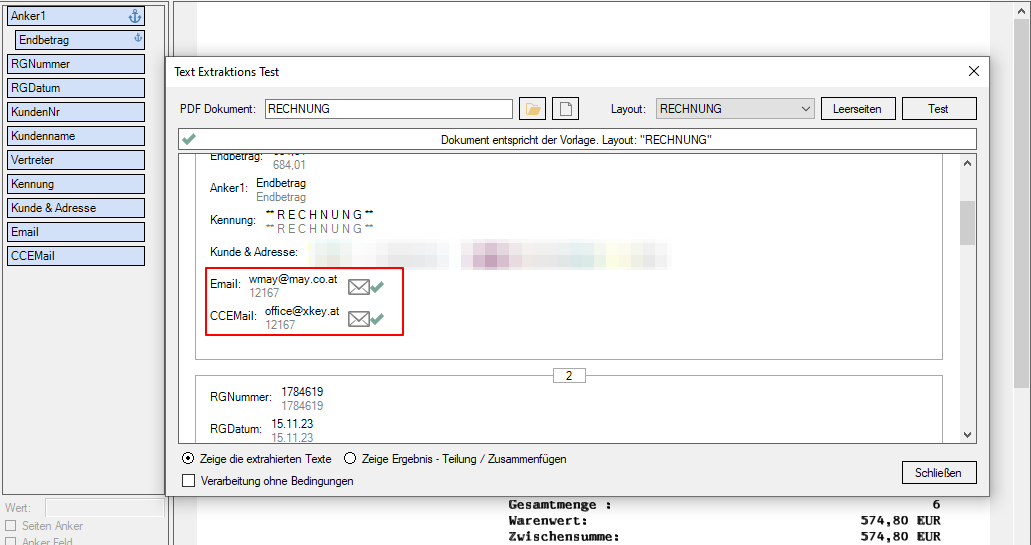
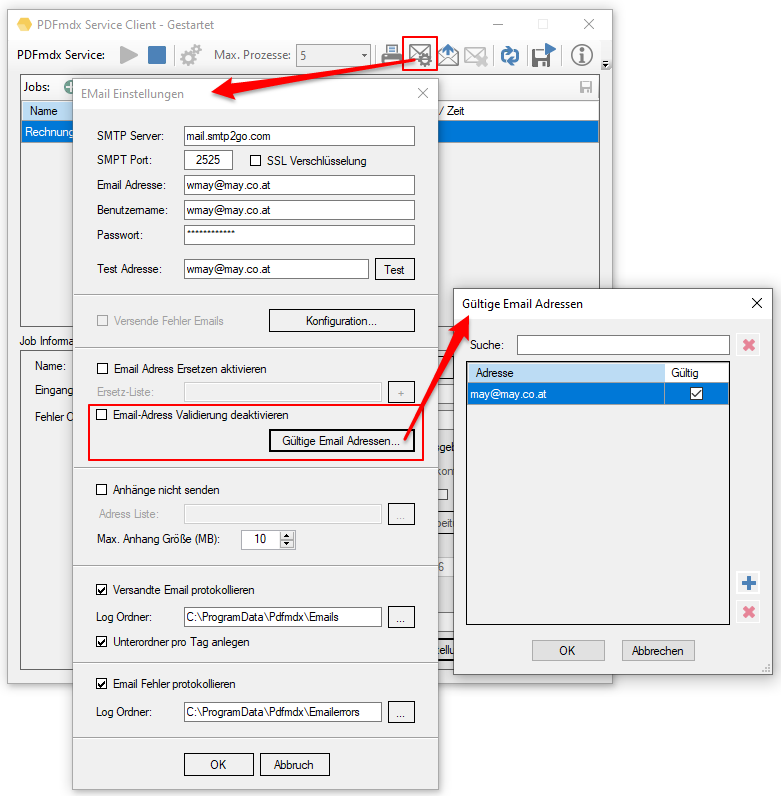
- EMail Adress Validierung: Dabei wird die ausgelesene bzw. über eine externe Tabelle gefundene EMail Adresse einer Validierung unterzogen. Dabei wird nach Kriterien und externen Abfragen festgestellt ob es sich um eine gültige EMail Adresse handelt oder nicht. Die Adresse Validierung kann auch deaktiviert werden. Ist sie deaktieiert so erfolgt lediglich eine Basis-Validierung nach „@“, nicht erlaubten Zeichen und doppelten Punkten am Beginn und Ende der EMail Adresse. Um dabei verhindern zu können dass an sich gültige EMail Adressen nicht angenommen werden, können solche auch explizit als „gültige Adressen“ in einer Tabelle hinterlegt werden. Für Variablen dieses Typs wird in der in der Test-Ergebnisanzeige des PDFmdx Editors der Status der Adress Validierung über einen „grünen Haken“ oder „rotes X“ angezeigt.
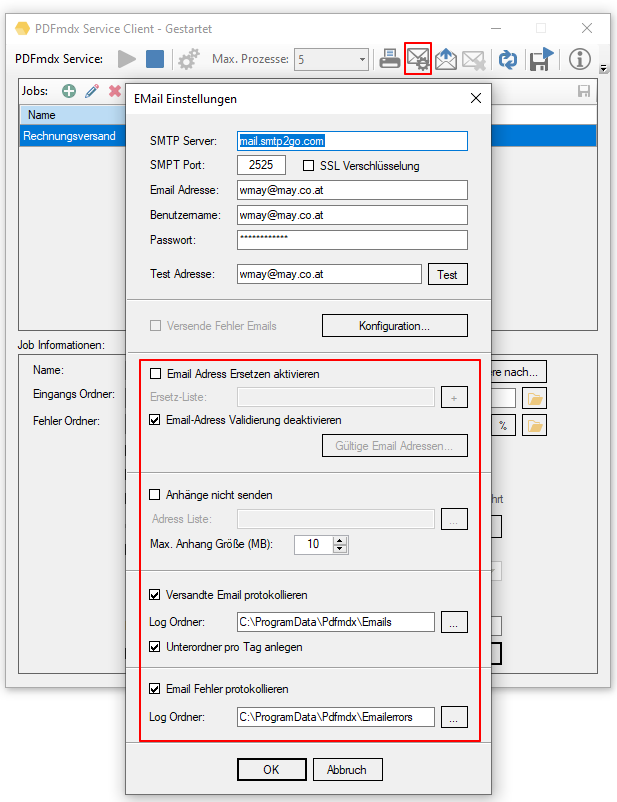
- EMail Adressen ersetzen: Über eine TXT Tabelle können ausgelesene EMail Adressen vor dem Versand durch andere EMail Adressen ersetzt werden.
- EMail Anhänge nicht an bestimmte EMail Adressen senden: Dabei wird über eine externe TXT EMail Adressliste gesteuert welche Empfänger keine Anhänge, sondern nur die EMail Nachricht alleine erhalten.
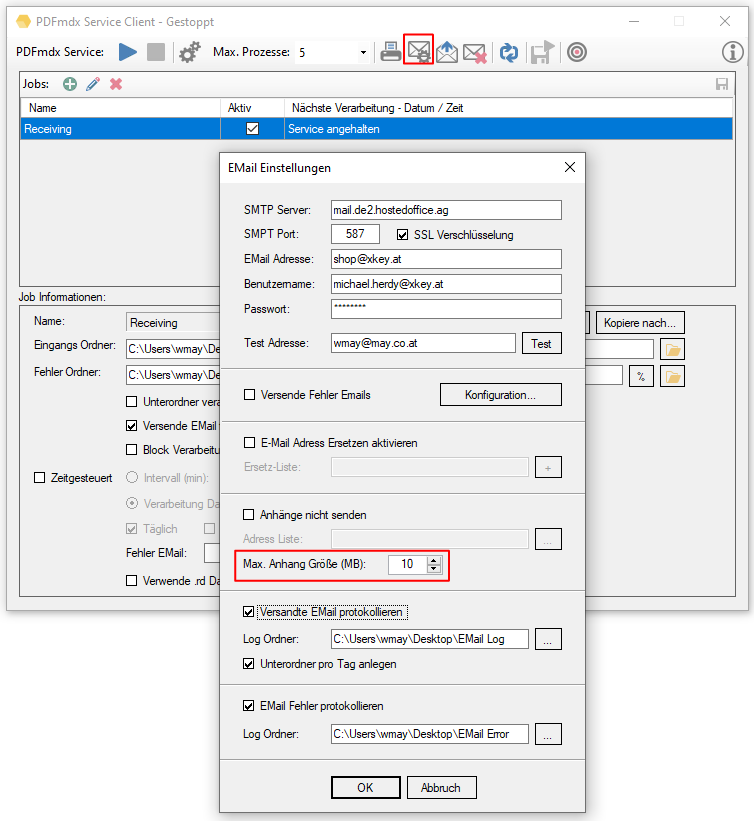
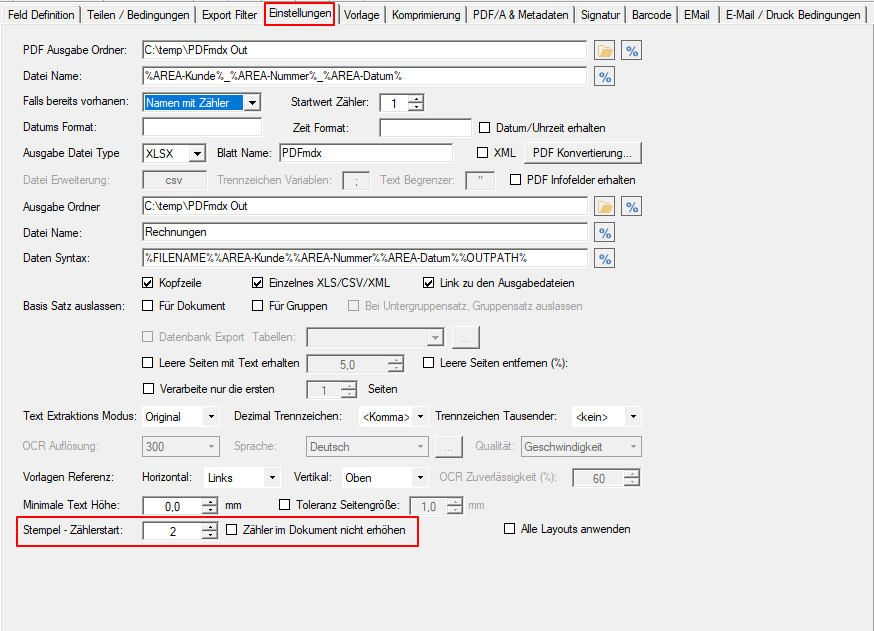
- Max. Anhang Größe: Dieser Parameter ermöglicht es die max. Größe der EMail Anhänge zu steuern. Wird für einen Empfänger die eingestellte Größe überschritten so erhält er autoatisch mehrere EMail Nachrichten mit Anhängen kleiner / gleich der eingestellten max. Größe.
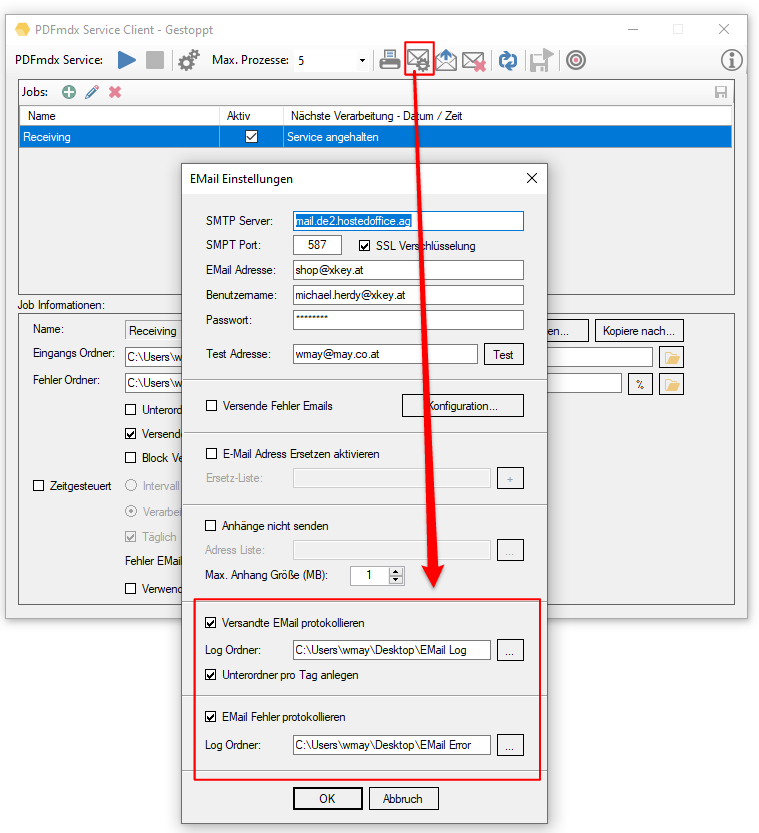
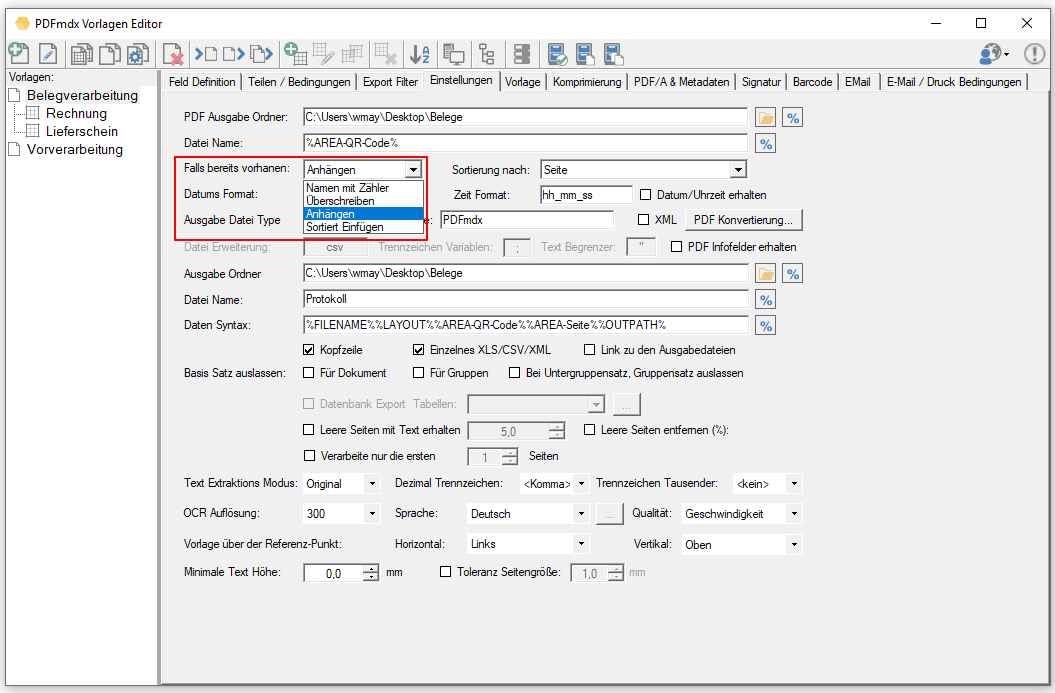
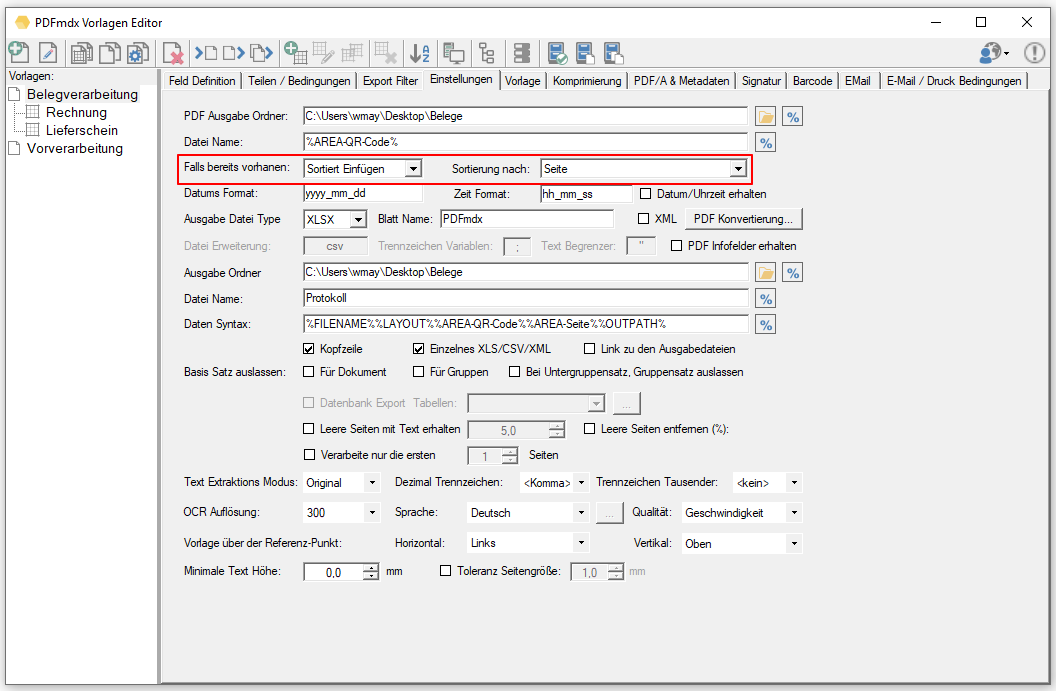
- Versandte / Fehler EMail als EML/XML protokollieren: Die Protokollierung kann aktiviert / deaktiviert, der Log-Ordner kann festgelegt werden. Dadurch erhält man eine lückenlose Protokollierung aller EMail Nachrichten die erfolgreich versandt wurden, bzw. auch jener Nachrichten die bei der Übergabe an den EMail Server einen Fehler erzeugt haben. Die Nachrichten werden im EML Format zusammen mit den Metadaten der Nachricht im XML Format im Log Ordner abgelegt und können im PDFmdx Prozessor aufgelistet und angezeigt werden.
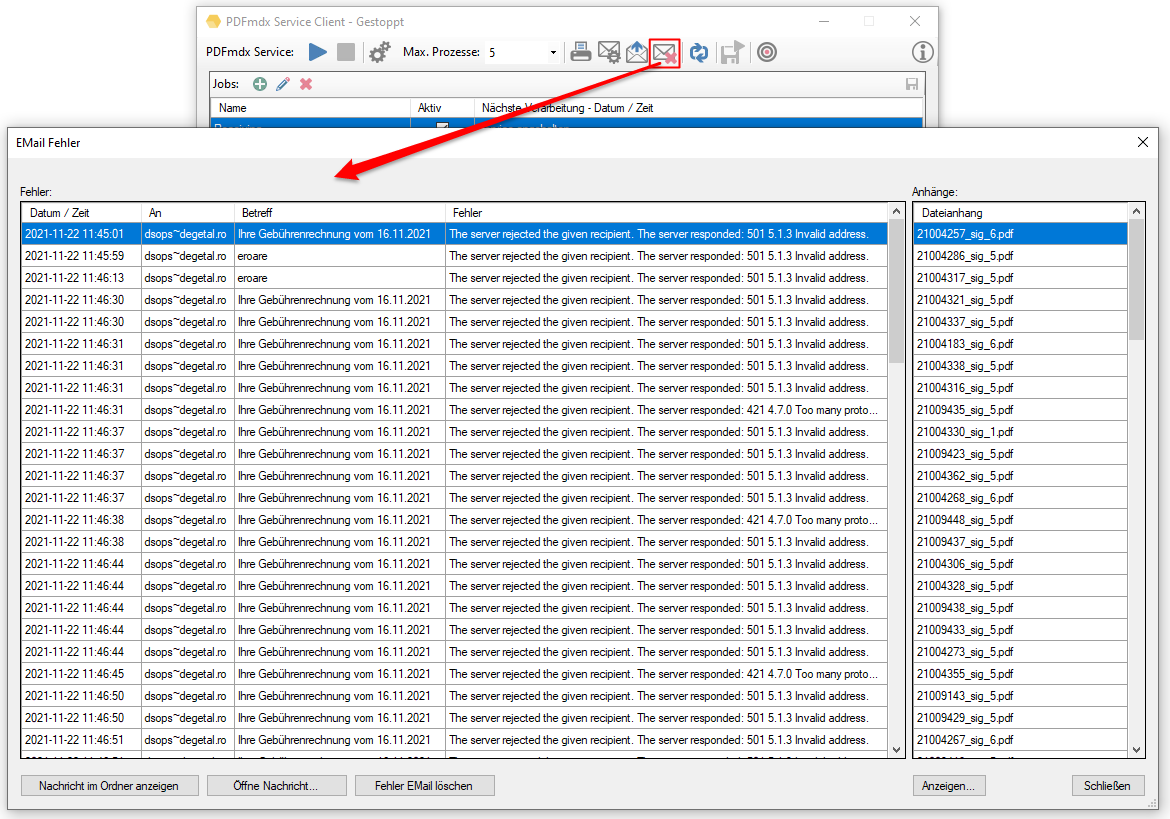
- EMail Log – Anzeige Funktion: Die versandten EMail können im PDFmdx Prozessor in Form einer Liste über Tagesordner getrennt abgerufen werden. Die Tabelle kann über die Spalten „Versandzeitpunkt“, „Empfänger“ bzw. „Betreff“ sortiert werden und zeigt in einer Liste rechts daneben, über deren Namen, die in der Nachricht enthaltenen Anhänge. Der Log Odner kann gelöscht oder geöffnet werden. Ebenso lassen sich die EML Nachrichten bzw. deren Anhänge über ihre verknüpften Anwendungen aufrufen und anzeigen.
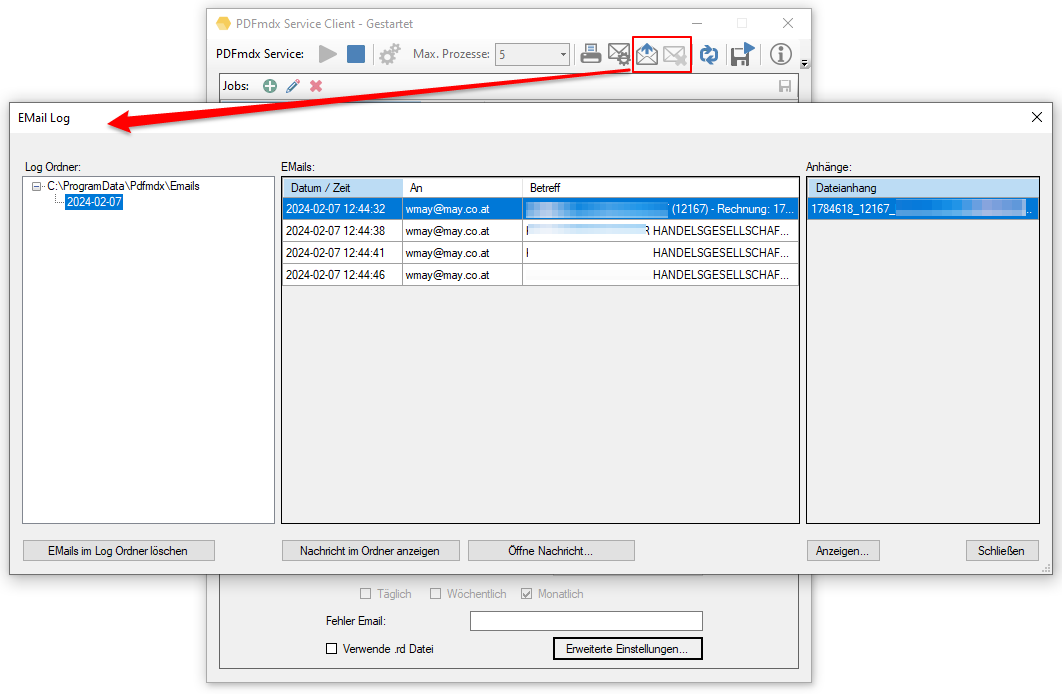
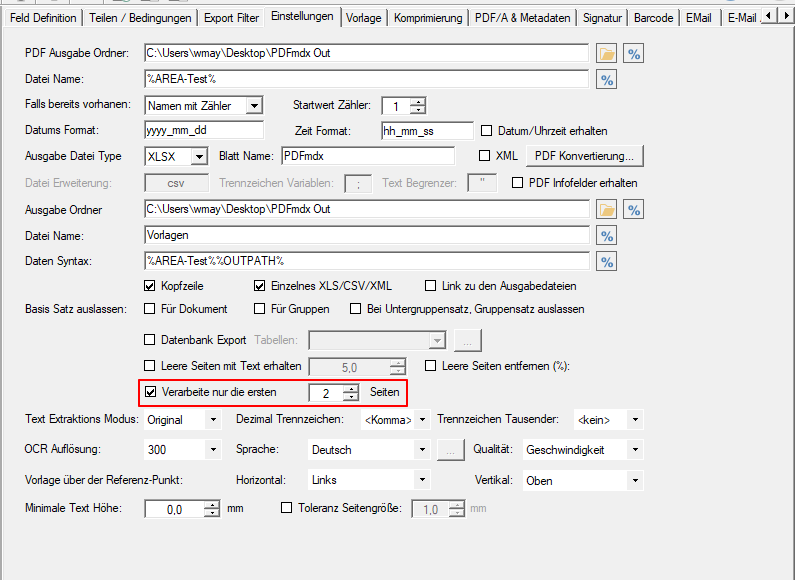
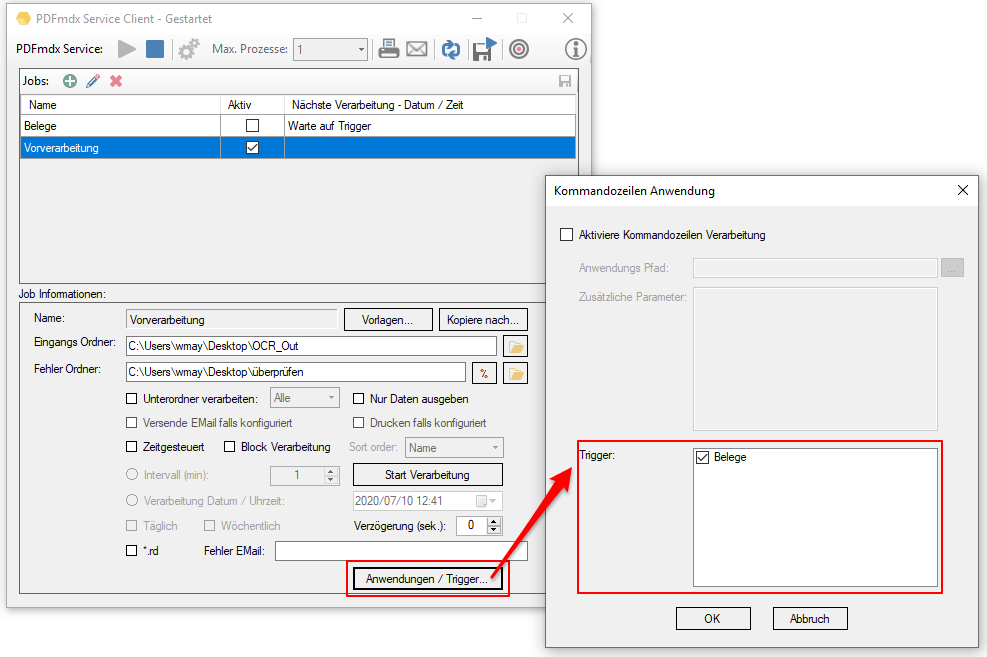
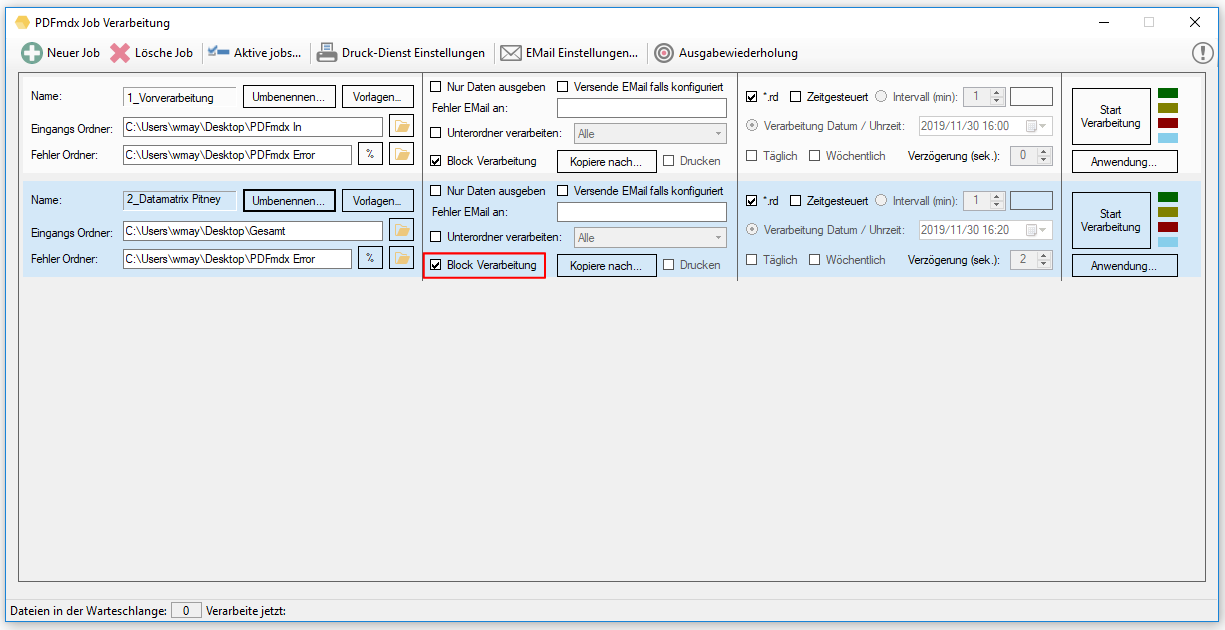
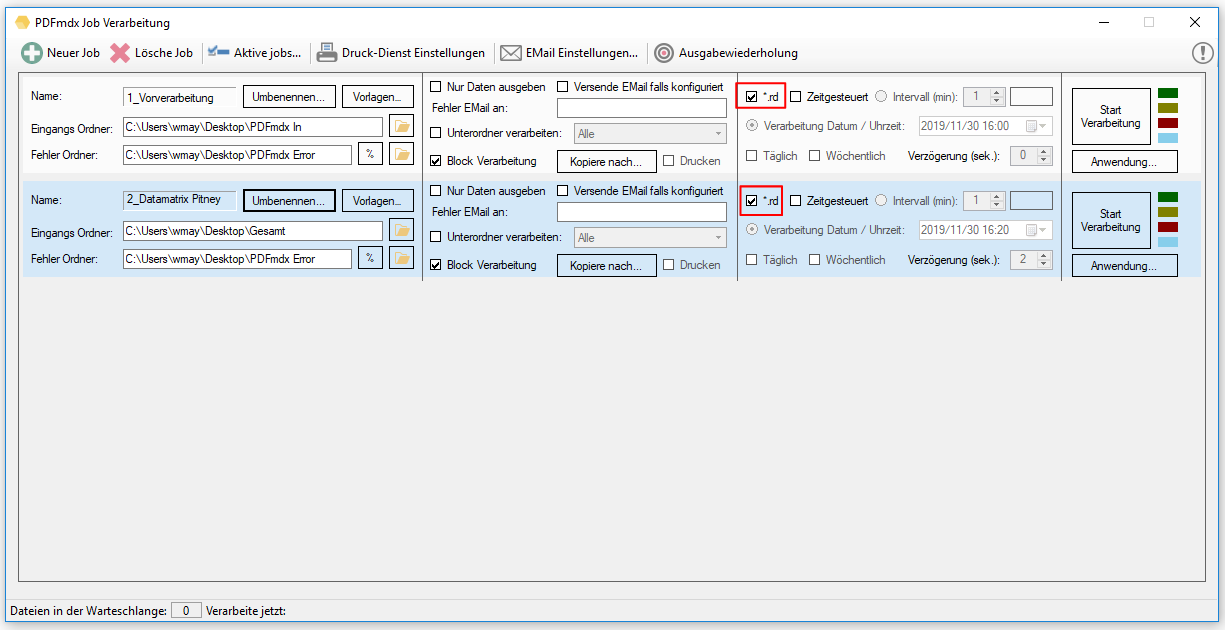
- Start der Verarbeitung – monatlich wiederholend: Neben der Intervallsteuerung – „täglich“ sowie „wöchentlich“ gibt es jetzt auch die Option die Verarbeitung „monatlich“ wiederkehrend durchführen zu lassen.
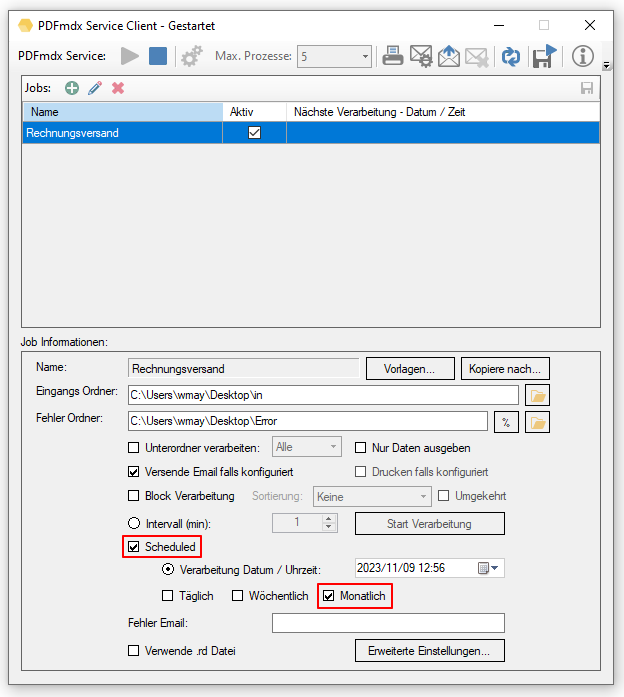
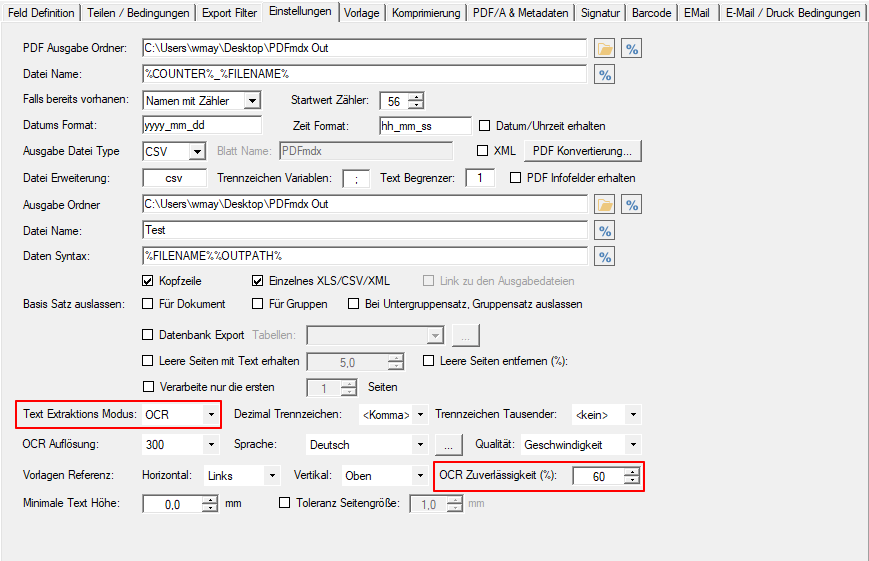
- Neuer Variablentyp „Spezial“: Auslesen von PDF Infofeldern bzw. Eingangs-Ordnername. Um auch Informationen aus anderen Quellen als über Bereiche aus dem Dokument einer Variable zuordnen zu können, wurde der neue Variablentyp „Spezial“ implementiert. Damit können felxibel weitere Quellen aus dem Dokument hinzugefügt werden ohne diese Variablen fix an allen Stellen im Programm Einzeln hinzufügen zu müssen. Damit lassen sich jetzt auch die PDF Infofelder: Titel, Autor, Betreff, Schlagworte 1-8 (durch „;“ getrennt), sowie der Eingangs-Ordnername einer Variable zuordnen und für die Verarbeitung verwenden.
Download – PDFmdx Template Editor & Processor >>>